
Automated Load Patterns based on Source Data Profiles, AgileData Engineering Pattern #4
The Automated Load Patterns based on Source Data Profiles pattern automatically profiles incoming data to determine its optimal loading pattern.
Automated Load Patterns based on Source Data Profiles
Quicklinks
Agile Data Engineering Pattern
An AgileData Engineering Pattern is a repeatable, proven approach for solving a common data engineering challenge in a simple, consistent, and scalable way, designed to reduce rework, speed up delivery, and embed quality by default.
Pattern Description
The Automated Load Patterns based on Source Data Profiles pattern automatically profiles incoming data to determine its optimal loading pattern.
It classifies data as either event data (immutable, append-only) or change data (evolving records) by analysing characteristics like unique key volume and column names over time.
This automated classification then dictates the load strategy: an efficient partition replace for event data or a cost-effective upsert (end-dating historical records) for change data.
This capability removes the manual burden and accelerates data onboarding, providing a trustworthy and efficient process even when the data type is initially unknown.
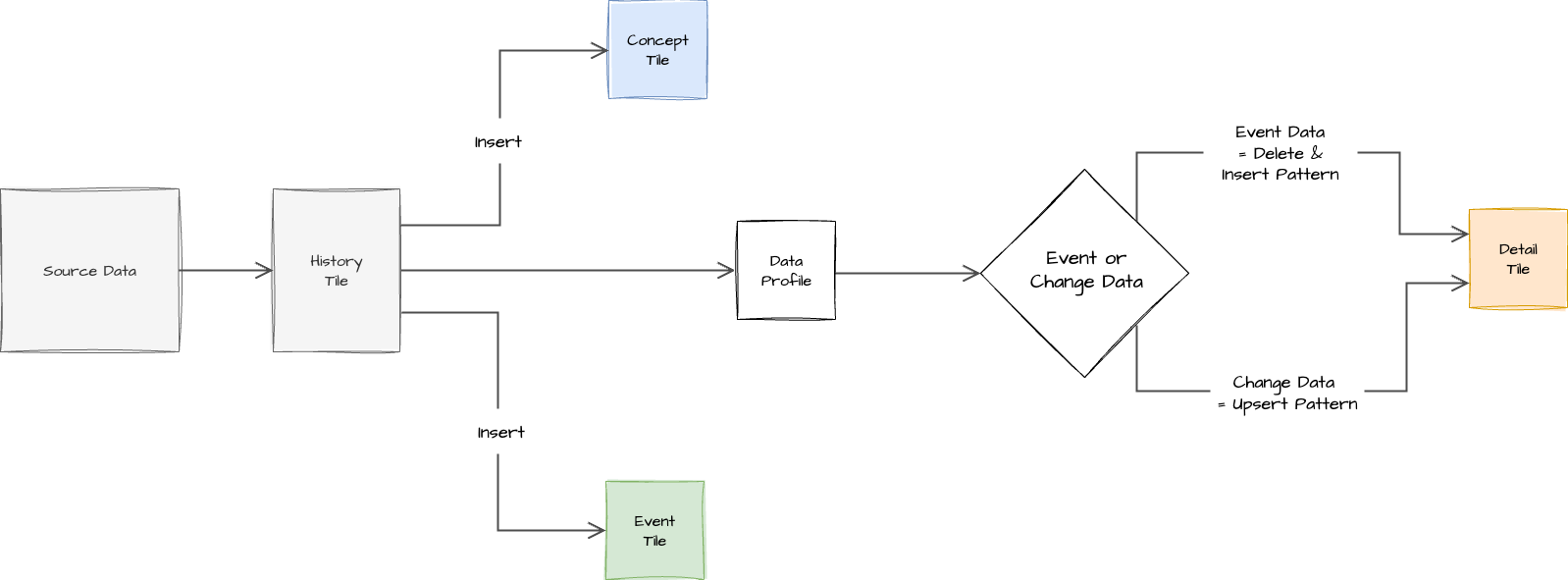
Pattern Context Diagram
Pattern Template
Pattern Name
Automated Load Patterns based on Source Data Profiles
The Problem It Solves
You know that moment when you receive new data from a customer or system, and you're not sure if it contains historical changes, is a stream of unique events, or a mix?
Manually figuring out how to load this data efficiently and correctly can be a real headache. It slows down data onboarding, requires a lot of manual thought, and if you pick the wrong approach, you could end up with duplicated data or incorrect historical views
This pattern solves that by automating the decision of which data load method to use, significantly speeding up onboarding and reducing the cognitive burden on data engineers.
When to Use It
Use this pattern when:
You're receiving new data with an unknown or uncertain structure – you're not sure if it's event data (immutable, append-only) or change data (records that might be updated over time).
You need to onboard data quickly, especially when prototyping new loads for customers.
Cost-efficiency and speed of data loading are crucial, as different data types benefit from different, optimised load methods.
You require auditing and accountability of changes, as the pattern helps manage historical data accurately by end-dating previous records.
You want an automated initial classification with a safety net for errors.
How It Works
This pattern functions like a smart data intake system, analysing incoming data to determine the best loading strategy.
Trigger:
New data arrives in your system, often a file dropped into a secure bucket.
Inputs:
The incoming data itself
Optionally, user-defined change rules that help classify the data.
Steps:
Data Classification: The system first classifies the incoming data into one of two primary types: event data (immutable, e.g., GA4 user views, sensor readings, which typically have event timestamps and event names) or change data (records that can change, e.g., customer status, order details, often linked by a business key).
Source Data Profiling: The system profiles the incoming data, typically looking back over a recent period (e.g., 90 days). This involves:
Analysing column names for identifiers common to event data.
Determining the "shape" of the data, such as how many unique keys appear per day. For example, if 200,000 unique customer IDs appear daily, it's likely event data; if only a few hundred change, it's more likely change data.
Applying thresholds based on known characteristics of event and change data.
Based on the profiling, the data is "lightly tagged" as either event or change data.
Load Pattern Determination: The system then uses this tag to select the appropriate load pattern:
For 'Concepts' data, which involves inserting new unique keys, an Insert pattern is always used, regardless of event or change classification.
For 'Details' data classified as Change Data, an Upsert pattern is employed. If a record is new, it's inserted. If an existing record's "row hash" has changed, the existing row is marked as 'ended' (end-dated), and a new row with the updated information is inserted. This is chosen for its cost-effectiveness due to partitioning and clustered keys.
For 'Details' data classified as Event Data, a simple Partition Replace pattern is used. Since event data is typically received only once as a stream, the system deletes the last couple of days of relevant partitions and then re-inserts those events. This is a very cheap and fast method as it avoids looking through the entire table for existing records
Automated Trust Rules: Post-load, "automated trust rules" monitor the loaded data. If the system's initial guess about the data type was incorrect (e.g., 1% of the time), these rules will trigger alerts, such as "unique key warnings" or "effective date" inconsistencies, indicating a potential misclassification that needs review.
Outputs:
Data that is correctly and efficiently loaded into the data platform using the most suitable pattern.
Early identification of potential data quality issues or misclassifications through automated alerts.
Why It Works
This pattern works because it's like having an intelligent gatekeeper for your data pipeline. Instead of a human needing to manually inspect and configure every new data source, the system takes on the burden of "cognition". It leverages the inherent characteristics of data (timestamps, keys, volume patterns) to make an informed, automated decision.
This leads to faster data onboarding, as teams can prototype new loads without knowing the data's exact nature upfront. The selection of specific load patterns (like cost-effective partition replace for events or end-dating for changes) ensures optimal performance and reduced processing costs.
Finally, the integrated "automated trust rules" act as a safety net, alerting you if the initial automated guess was off, turning potential errors into actionable insights and maintaining data trustworthiness.
It builds a system that hints at the right approach and then tells you if it's going wrong, allowing for quick corrections
Real-World Example
Imagine a new client starts sending you daily data dumps into a secure cloud storage bucket. One day, they send a file named web_analytics_clicks.csv.
With the Automated Load Pattern Selection pattern, when web_analytics_clicks.csv arrives, the system automatically profiles it.
It observes that each record has a unique click_timestamp and that hundreds of thousands of unique records (like "GA4 user viewed page" events) appear daily.
Based on this profile and volume, it correctly tags it as event data. The system then automatically selects and executes a Partition Replace load pattern, efficiently deleting and re-inserting the latest days of click data.
A few weeks later, the same client sends customer_master_updates.csv.
The system profiles this file.
It identifies a customer_id as a business key and notes that while the volume of new customer IDs is low (e.g., 100-1000 per day), existing customer records occasionally show changes in fields like customer_address.
This pattern is recognised as change data, prompting the system to automatically select an Upsert load pattern. This means if a customer's address changes, the old record is effectively "end-dated" by the system, and a new record with the updated address is inserted, maintaining a full history of changes cost-effectively.
If, by chance, the system misclassified a very low-volume event stream as change data, "automated trust rules" would trigger an alert for "unique key warnings" because of unexpected duplicates, prompting a human review
Anti-Patterns or Gotchas
Drastically Different Data Profiles: The pattern can be tripped up if the incoming data's characteristics dramatically change or are unusual for its type. For example, if an event stream suddenly has a very small volume (e.g., 5-10 events a day instead of thousands), the system might misclassify it as change data, leading to key errors and duplicate records on subsequent loads.
Ignoring Automated Trust Rule Alerts: If the system guesses incorrectly (which happens in about 1% of cases), it will generate alerts (e.g., "unique key warnings," duplicates, or issues with effective dates). Ignoring these alerts will lead to untrustworthy data and broken processes, defeating the purpose of the pattern.
Over-reliance without Understanding: Simply letting the system do its thing without understanding the underlying data types or the logic of the chosen patterns can lead to confusion when errors do occur, requiring manual intervention to correct configurations.
Tips for Adoption
Trust the Automation (Initially): For new data, "let the system do that quick profile for us". This allows for much quicker prototyping and onboarding.
Heed the Trust Rules: Pay close attention to the "automated trust rules". These are your early warning system for misclassifications or data quality issues.
Understand Profiling Thresholds: Be aware that the system uses "thresholds based on what we know event data tends to look like". For very unusual data volumes, a manual check might be necessary, or the system might flag it for review.
Consider AI Enhancements: As the data landscape evolves, explore using AI (e.g., LLMs) to provide better "hints" or "judge type patterns" to decide when profiling is unclear or volume is insufficient.
Combine Patterns: The strength of this approach comes from "racking and stacking those patterns together to automate that work" – integrating profiling with specific load patterns and automated validation.
Related Patterns
Automated Trust Rules: This pattern is highly complementary, as it validates the accuracy of the automated load pattern selection and alerts on issues.
Schema Detection: Can work in conjunction, especially when initial profiling is inconclusive, to infer data structure and further inform load pattern decisions.
Judge Type Pattern: A potential advanced pattern to resolve ambiguities when the automated profiling struggles to definitively classify data (e.g., very low volume events).
Specific Load Patterns Enabled: This pattern selects from established data loading patterns such as:
Insert Pattern: For append-only data like 'Concepts'.
Upsert Pattern: For managing changes in 'Details' data by end-dating previous records and inserting new ones.
Partition Replace: A highly efficient method for loading 'Details' event data by replacing specific data partitions.
End-Dating: A key component of the Upsert pattern for managing historical versions of records
Press Release Template
Capability Name
Automated Data Loading with Smart Profiling
Headline
New Automated Data Loading Feature Accelerates Data Onboarding and Boosts Trustworthiness for Data Teams and Users
Introduction
Today, the Data Platform team is excited to announce the launch of our new Automated Data Loading with Smart Profiling capability. This revolutionary feature automatically determines the optimal way to load incoming data, removing manual guesswork and significantly speeding up the process of getting new data into your analytics systems. It's designed for anyone who needs to bring data into the platform, ensuring efficiency and accuracy from the first moment.
Problem
"As a data engineer, when new data arrives – especially from external sources – I always have to spend time figuring out if it's event data, change data, or something else. This manual classification slows down onboarding new data sources and carries the risk of picking the wrong load method, leading to data quality issues like duplicates or incorrect historical views. I wish the system could just figure it out for me!".
Solution
Our new Automated Data Loading capability intelligently profiles incoming data to automatically determine its 'shape' and optimal load pattern. When new data arrives, the system first classifies it as either event data (immutable streams like user views or sensor readings) or change data (records that update over time, like customer details or order statuses).
The system achieves this by:
Profiling the source data over a recent period (e.g., 90 days), analysing factors like the number of unique keys appearing per day and common column names associated with event data. For instance, if millions of unique records appear daily, it's likely event data; if only a few hundred changes occur, it's probably change data.
Lightly tagging the data based on this profile.
Automatically selecting the most efficient load pattern:
For 'Concept' data (new unique keys), a simple Insert pattern is always used.
For 'Detail' data classified as Change Data, an Upsert pattern is applied. This means if a record is new, it's inserted; if an existing record has changed, the previous row is automatically 'end-dated', and a new row with the updated information is inserted, maintaining full history cost-effectively.
For 'Detail' data classified as Event Data, a Partition Replace pattern is used. Since event data is typically append-only, the system efficiently deletes and re-inserts only the most recent partitions of data, avoiding expensive full-table lookups.
This automated approach removes the manual burden and potential for errors. Furthermore, automated trust rules monitor the loaded data, alerting users to potential misclassifications (e.g., unexpected duplicates or effective date inconsistencies) if the system's initial guess was incorrect, ensuring data trustworthiness and providing a safety net.
Data Platform Product Manager
"With Automated Data Loading with Smart Profiling, we're removing the cognitive burden from our data engineers, allowing them to onboard new customer data significantly faster and with greater confidence. This capability enhances the trustworthiness and auditability of our data assets by ensuring the correct load patterns are applied, and crucially, it actively flags any data quality issues that arise from misclassification, turning potential problems into actionable insights."
Data Platform User
"I absolutely love that I can just drop new data files into our secure bucket, and the system automatically figures out the best way to load them. It’s incredibly fast, and I don't have to worry about complex configurations or whether I'm managing changes correctly. It just works, making my job so much easier and giving me trusted data right away!”
Get Started
You can start benefiting from Automated Data Loading with Smart Profiling immediately. Simply provide your data files as usual, and the system's intelligent profiling will do the rest, automatically applying the most efficient and correct load pattern. For more information on how this capability works or to understand the trust rules, please contact your data platform product manager.
AgileData App / Platform Example
Concept / Detail / Event Rules Logic
Concept = Insert

Detail = Upsert
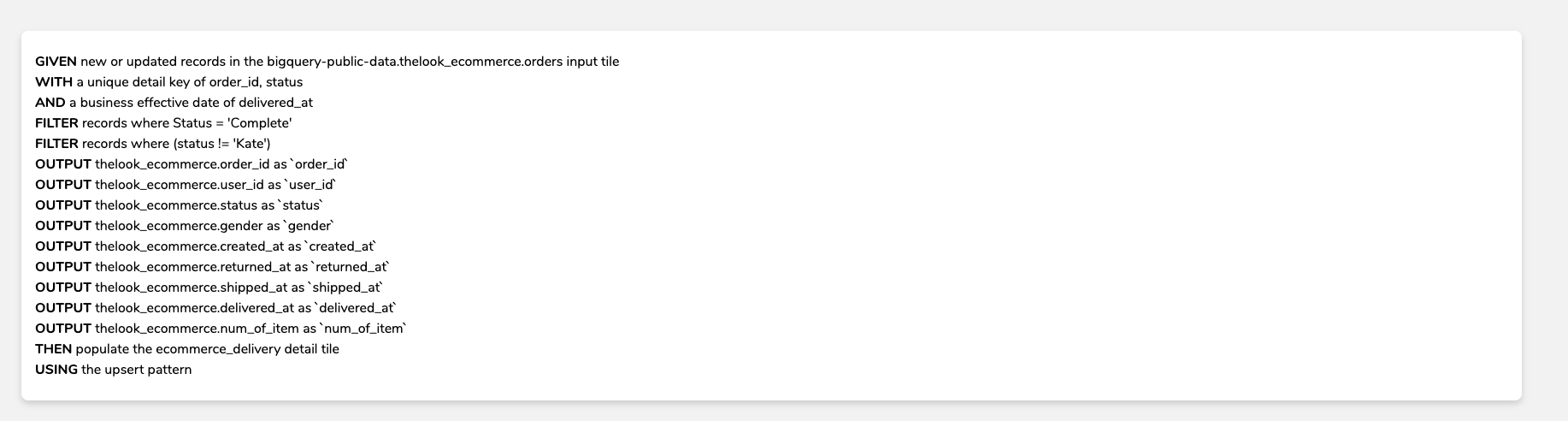
Event = Insert

AgileData Podcast Episode
AgileData Podcast Episode MindMap
AgileData Podcast Episode Transcript
Shane: Welcome to the Agile Data Podcast. I'm Shane Gibson.
Nigel: And I'm Nigel Vining.
Shane: Hey, Nigel. Today, another data engineering Pattern. This time we're gonna talk about automated load patterns based on source data profiling. So take me away with what it is and why I care.
Nigel: This one's quite an important one, and it underpins our product in lots of ways. So essentially we have, we classify the two types of data that turn up in our projects as event data. Think GA4 user viewed page or sensor type data which captured a reading of something or change data info about a customer.
Customer changing status, customer changing address, orders, order is created and order is processed. We do a little bit of magic when you data turns up and we look at the data to determine the shape. If we think it's event data or change data, event data is generally quite clear cut because it will have event timestamps.
You'll have an event name. It'll have attributes that basically give us pretty good clue that it's event data. But what we also do is we look basically back over the last 90 days. Of that data and we profile it to see what shape of it. How many records are turning up each day based on the timestamps or the business key that we know.
So if we have business keys and we see changes of the data in the business key, we're fairly confident that it's changed data. So once we know. Whether the data is event or change data, we lightly tag it and then what we do is when we go to load it, this is where we determine which load pattern where we use.
So you know, we use concepts, details, events, concepts we always use in. Insert pattern and that's fine. Whether it's event data or change data, it doesn't matter. All we're doing is inserting a new key when we see it. When we get to detail about the data, this is where we change. So for change data we run in upsert pattern.
So if it's change data we haven't seen before, we insert it. If it's change data, . We already have, but it's changed. The row hash has changed. Then we update the existing row to mark it as effectively ended and we insert a new row. Whereas if it's event data, event data is generally only given to us once.
Cause it's just a long stream of something happened, something happened, something happened. So what we use for that is we don't need to go looking back through the whole table to see if we've got it. We use a simple partition replace and we basically just delete the last couple of days of petitions and then we insert those events again.
So we're always basically putting the new events and at the end of the table and we don't go looking for them. Cause this is a really cheap and fast pattern. So that's effectively what we're doing with this pattern.
Shane: So we're looking to say as the data we're being given immutable it's an event that happened. We'll never be given that exact same event again. That event never changes. So that's typically, gA fours where we use it a lot. Somebody viewed a webpage. And then if it is, then we do an insert Pattern ,
we just basically insert those records because we know, we don't have to worry about whether they have changed or not. 'cause they're all immutable and new. Otherwise it's a different Pattern where we know the data might change. Probably comes from some form of relational schema in the source system.
So we know that, the customer name might change or the customer address might change or the order quantity may change. And we therefore have to manage those changes and rack and stack them. So that's, so therefore we do an upset Pattern , where effectively, end date, the previous record and insert the new record
Nigel: correct, yes,
Shane: That end dating is quite an old Pattern , it's a bit of a ghost of data past. Why don't we do that fancy one where we don't end data and then just leave the insert dates and then go through into a whole lot of windowing functions whenever we need to determine what is the latest record.
Nigel: a lot of that's round cost we partition by those dates so we can quickly look at the current data. If we weren't to do that, it means we would be looking across. Potentially all the rows in the table every time for each business key to find out where that record started and ended.
So there's a lot more overhead to do it dynamically, whereas to do a quick look up because it's a partition and a clustered key, we can do it and endate the record very cheaply.
Shane: Cool. So it's a cost decision that we've used to pick that Pattern.
Nigel: That's exactly right. We could definitely do it with a lot less Complexity just to load all the records and then at the end do a window as you said, look for the latest record and mark it as current, but that's more processing. We have to read more data to do that pattern.
Shane: Talk me through the way the profiling works, how does it actually determine whether it thinks it's an event or change data?
Nigel: So the profiling is based on the change rule that the user creates, so the user will create rules, say in this case a. concept rule to load a concept tile. Once we have that rule, we can effectively run that rule and bucket the results that come back to work out how many unique keys are appearing.
Per day and we also check the column names as well looking for identifiers that we know that event data typically have, but profiling generally tells us because if we are getting lots of unique keys turning up every day, it's generally indicative of event data because you don't create say 200 ,000 customer IDs every day.
You may create. You know, 100 or 1000, but not large volume. So if we see 200 ,000 keys turning up every day, those are probably all unique event keys and we're pretty safe with that. So we use some thresholds in there based on what we know event data tends to look like.
Shane: And why do we do it? Like why don't you just force me to tell the system what kind of data it is when I start to collect it.
Nigel: that's a good question. We're effectively. Removing a little bit of cognition from your load and also what happens is it means we can onboard data a lot quicker because typically when we prototype a new load for a customer, we just keep giving a file. We may not know if it's event or change data. We just load that file.
And effectively we lead the system do that quick profile for us so you can happily go and create rules on that in 99 percent of the time it's going to go cool. It's event data and a load like this you say. Great, it's changed data below like this. The 1 percent of the time that we get our guests wrong, it'll still load, but effectively we would generally find that the second load throws a few errors and warnings because we're not loading the data quite right.
Shane: And that's where the trust rules come in, those automated trust rules will give us an alert to say this has been flagged as event data, but we are starting to see that the customer key is constantly getting change records coming through. That's an anti-patent for the patent that you've been selected.
Therefore, you probably need to go and change the config in context and rebuild some stuff so that it's safe, it’s trustworthy.
Nigel: that's exactly what happens. Effectively, the first thing we get is usually a unique key warnings because we're always checking for unique records. If we're not loading the data quite right, it'll start to create duplicates very quickly. The other thing we check for is the effectivity date. Of those records, because if we're getting lots of records turning up with the same effective date and we're trying to update based on that, it's also an indication that we possibly using the wrong pattern because we don't have an effective date for each business key.
So it's more likely to be event data.
Shane: And then Antipas where wouldn't you use this? Or what's the gotchas? You gotta watch out for?
Nigel: The anti pattern is where we get data turning up. That's very different to what we've seen and what we're based our profile on. Like an example would be event data, but very small number of events. Say you know five or 10 events a day, whereas typically events are in the magnitude of thousands, tens of thousands, hundreds of thousands.
You wouldn't expect to see. Four or five events being created each day, so that would trip us up. We would go. Oh, that's changed data. Is that volume so low and it would load right for a day and then we would on day two would start to get key errors because it would start to duplicate the data.
Shane: I like the way it effectively gives us a hint, that picks it for us. And then if something goes wrong, it tells us and we can fix it. I like. That because often we have customers that just send us their data, so they're not comfortable with us reaching in and collecting it, connecting internally to their systems or their cloud systems.
So we give them a secure bucket and they effectively just dump some data in there and we've never seen it before. So this helps us do that first bit of design around that data. I think with the new AI wave, there'll be some interesting ways we can enhance it. In theory as we see more and more systems, we could actually use that as a hint to one of the LMS to actually say, here's all the patterns of data we've seen before.
And then we could actually tag certain systems like google Analytics to say it is event data so that when we get, a customer that's only got three events happening through Google Analytics on a daily basis, it's gonna drop back to say, volume's too small. Let's go look at some of the other patterns and use a judge type Pattern to decide which one wins and also flags it to say not enough volume to actually determine the profile properly.
Fill back to schema detection. you probably want to go and look at this one and just check it or wait to see if you get any alerts to say the data's not so trustworthy. It's all about racking the, stacking those patents together to automate that work. Excellent. I hope everybody has a simply magical day.