
AgileData Data Match, AgileData Engineering Pattern #7
The Data Match pattern provides an automated, granular comparison capability to efficiently identify and report discrepancies between two datasets, moving from row counts to specific data values.
Data Match
Quicklinks
Agile Data Engineering Pattern
An AgileData Engineering Pattern is a repeatable, proven approach for solving a common data engineering challenge in a simple, consistent, and scalable way, designed to reduce rework, speed up delivery, and embed quality by default.
Pattern Description
The Data Match pattern provides an automated, granular comparison capability to efficiently identify and report discrepancies between two datasets, moving from row counts to specific data values.
This 'data diff' solution transforms hours of manual data reconciliation into minutes by optimising comparisons for cloud analytics databases like BigQuery, serving as a support feature for on-demand exception handling rather than a continuous trust rule.
Pattern Context Diagram
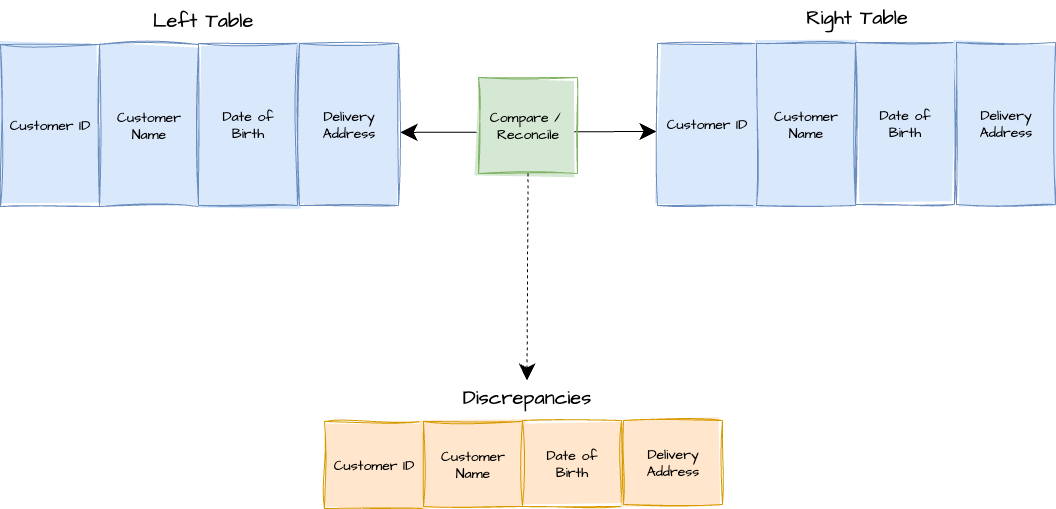
Pattern Template
Pattern Name
Data Match
The Problem It Solves
You know that moment when you're trying to figure out why your data numbers don't add up between two systems or tables? Or you're trying to check if everything from your source has made it to your target?
Often, you're faced with hours, or even days, of painstaking manual reconciliation, writing complex SQL queries, or dealing with inefficient brute-force comparisons that cost a fortune in compute resources.
This pattern solves the problem of quickly and efficiently identifying discrepancies between two datasets, saving immense time and frustration.
When to Use It
Use Data Match primarily as an exception thing or a support feature. It's most useful:
When something goes wrong and you suspect data misalignment between a source and a target.
For reconciling data after a migration or a complex transformation, especially when trying to pinpoint missing records.
When you need to quickly compare two tables or datasets to find differences without writing custom SQL.
When manual reconciliation is proving horrendous due to large volumes or complex logic.
It's not designed as a core trust rule for every data movement, but rather for on-demand verification.
How It Works
This pattern turns a complex data reconciliation task into a few simple clicks.
Trigger: A user needs to verify data consistency between two datasets because a discrepancy is suspected, or an audit is required.
Inputs:
A "table on the left" (source data) and a "table on the right" (target data). This could include data uploaded from an Excel spreadsheet as a "new tile".
Specific "things in each table they want to double check", such as primary keys or particular columns.
Access to a data catalog where all relevant "tiles" (data assets) are loaded.
Steps:
The user selects the first dataset (e.g., "tile A") and the second dataset (e.g., "tile B") from an interface.
The user specifies the columns or keys within each dataset that need to be compared.
The user initiates the comparison, often with a simple "hit go" or a "1 2 3 4 five click exercise".
Under the covers, the system performs an increasingly granular match:
It starts by comparing row counts.
Then, it compares keys between the two tables.
Finally, it compares specific data values (e.g., "date of births"). This layering of rules optimises the comparison and avoids costly brute-force operations.
The system optimises the underlying queries for the specific database environment (e.g., BigQuery), leveraging features like column storage and partition pruning for efficiency.
Outputs:
A report detailing "all the things in the left that aren't in the right or vice versa".
Specific identification of discrepant records, such as a list of "customer IDs that haven't flowed".
Why It Works
Data Match works because it automates and optimises a typically complex and manual process. It replaces hours of writing and running custom SQL with an intuitive, guided workflow, essentially providing a "data diff" capability as a service.
The pattern's effectiveness comes from its layered approach to comparison, moving from high-level checks (like row counts) to granular value comparisons, which makes it highly efficient and cost-effective, particularly for large datasets in cloud analytics databases.
It's like having an automated detective that quickly sifts through vast amounts of data to highlight the exact discrepancies, allowing analysts to focus on why the data is different, rather than how to find the differences.
Real-World Example
Consider a scenario where a data engineering team is trying to reconcile customer data that has been processed through new business rules with an existing Excel spreadsheet used by the business. Despite their efforts, they constantly find themselves "one customer out" after processing 100,000 customers, and each discrepancy is for a different, often obscure, reason. Manually finding that single missing customer is a "horrendous" and time-consuming task.
With Data Match, the team can quickly upload the Excel data as a new "tile," then use Data Match to compare it directly with their processed customer data. The tool rapidly highlights the exact single record that is out, turning "many hours of frustration" into "minutes" of investigation. This allows the team to spend their time understanding the root cause of the discrepancy with the business, rather than painstakingly searching for it.
Another example involves a data migration project where 100,000 customer records were sent via an API to a new vendor system, but only 80,000 appeared in the new system. Manually debugging this took "hours if not days". If Data Match had been available, they could have "back flushed" the final data loaded by the vendor as a "tile" and then compared it with the data they sent. This would have immediately identified the 20,000 records that didn't make it, saving significant time and effort in proving where the discrepancy occurred (e.g., showing the vendor that changes were made on their side, despite an agreement not to).
Anti-Patterns or Gotchas
Brute-Force Comparisons on Large Datasets: Trying to match everything between two very large tables without any optimisation or "layering of rules" will be extremely costly in terms of compute, credits, or tokens.
Using Non-Optimised Tools: Relying on generic open-source libraries that are not specifically optimised for your cloud analytics database (e.g., a tool skewed towards row storage databases like Postgres when you're using a column-oriented database like BigQuery) will lead to inefficient queries and high costs, failing to leverage the database's performance benefits.
Overuse as a Primary Trust Mechanism: Data Match is an "exception thing," not a core "trust rule" to be run for every data movement. Over-relying on it for continuous validation can be inefficient and indicates a potential gap in proactive data quality monitoring.
Tips for Adoption
Implement for On-Demand Use: Position Data Match as a powerful, on-demand "support feature" for when anomalies occur or specific reconciliations are needed, rather than an always-on data quality check.
Optimise for Your Platform: If developing an internal version, ensure it's specifically tailored and optimised for your primary data platform (e.g., BigQuery) to maximise efficiency and minimise costs.
Integrate with Data Catalogues: Make it easy for users to pick and compare any "tile" (data asset) loaded in your data catalogue, reducing the overhead of manual configuration.
Focus on Post-Detection Analysis: Emphasise that Data Match quickly identifies what is different, enabling data professionals to then spend their valuable time on why the data differs and how to fix it.
Related Patterns
Data Diff: This is the general term for the concept that Data Match embodies.
Tracing Values: This related feature helps users specifically look for the flow of individual data points once discrepancies are identified by Data Match.
Press Release Template
Capability Name
Data Match
Headline
AgileData Launches Data Match to Slash Data Reconciliation Time from Hours to Minutes for Data Teams
Introduction
AgileData is thrilled to announce the availability of Data Match, a powerful new capability designed to simplify and accelerate the process of identifying discrepancies between two datasets. This feature empowers data analysts, engineers, and business users to quickly verify data consistency and pinpoint missing or mismatched records with unprecedented ease, ensuring greater confidence in their data.
Problem
"As a data professional, I've spent countless hours, sometimes even days, painstakingly trying to figure out why my numbers don't match between two systems or after a data migration. It's a horrendous, manual process of writing complex SQL or sifting through spreadsheets, often just to find that one elusive missing record. I just want to know what's different, quickly, so I can fix it."
Solution
Data Match transforms this laborious task into a quick, intuitive process. Users simply select two datasets (or "tiles"), specify the keys or columns they wish to compare, and with a few clicks, the system performs an optimised, granular comparison. It efficiently checks everything from row counts to specific data values, then generates a clear report highlighting all discrepancies. This eliminates the need for manual SQL queries and immediately pinpoints the exact records that are out of sync, saving hours of frustration and compute costs.
Data Platform Product Manager
"With Data Match, we're not just offering a new feature; we're fundamentally improving trust and auditability within our data ecosystem. It provides our users with an on-demand, highly efficient tool to quickly validate data alignment, ensuring that discrepancies are identified swiftly, reinforcing confidence in our data pipelines and overall data quality."
Data Platform User
"Honestly, Data Match is a game-changer. What used to take me 'hours, if not days,' to manually reconcile data or prove a discrepancy, now literally takes 'minutes' with just a few clicks. I don't have to remember complex queries; I just hit 'go' and get my answers, letting me focus on solving the why, not just finding the what."
Get Started
Ready to transform your data reconciliation process from hours to minutes? Data Match is available now within the AgileData platform. Connect with your AgileData team today to learn more about how to leverage this powerful capability, or visit agiledata.io for further details on adopting new patterns to craft your Agile Data way of working.
AgileData App / Platform Example
AgileData Podcast Episode
https://podcast.agiledata.io/e/data-match-agiledata-engineering-pattern-7-episode-75/
Subscribe: Apple Podcast | Spotify | Google Podcast | Amazon Audible | TuneIn | iHeartRadio | PlayerFM | Listen Notes | Podchaser | Deezer | Podcast Addict |
AgileData Podcast Episode MindMap
AgileData Podcast Episode Transcript
Shane: Welcome to the Agile Data Podcast. I'm Shane Gibson. And I'm Nigel Vining. Hey, Nigel. Another data engineering bytes. Today we are gonna talk about a feature that we term data match. So tell me what it is and why I care
Nigel: Data match. Came out of the age old question, how do I know something in my source is in my target?
Or as we like to say, what's in the left isn't in the right or vice versa. This is generally called a data diff in a lot of places. Generally, it's a Pattern of doing an increasingly granular match of something on the left, which is generally a table of. Data and something on the right. So we start off and we say, is the number of records the same?
Yes, it is. Great. Cool. Are all the keys the same between these two tables? Yep, they are. Cool. Now is the date of births on the table on the left the same as the date of births on the table. And we effectively, we go from the very wide row count down to something very specific. Do the actual values match from left to right?
Now that all sounds pretty straightforward and it technically is, but under the covers there's a whole lot of SQL and engineering patterns that are happening to basically run all those queries. So that's not something we would expect a analyst to generally do 'cause it's a bit of a faf. So we came up with this feature called Data Match, where we effectively lead a user.
Pick a table on the left. Pick a table on the right. Pick the thing in each table. They want to double check and hit, go under the covers. Then we optimize those comparisons and then we produce a report straight back to the user saying these are all the things in the left that aren't in the right, or vice versa.
So we've made it a 1, 2, 3, 4, 5 click exercise and you can reconcile anything in your environment and it's.
Shane: I think this one from memory was an interesting problem. So we had a customer that we were doing the data work for. They had a series of business logic or rules that was in a fairly horrendous Excel spreadsheet.
So we used our way of working and we extracted the, the. Concept of those rules and we modeled the data properly and we applied those rules. And whenever we were trying to reconcile the numbers we got with the numbers in the spreadsheet, we were always one thing out. So let's just say it was a reconciling customers, they would have a hundred thousand and one customers.
We would have a hundred thousand customers. So we'd manually go through, find that one customer, work out that it was a timing problem or make sure we ran it at the same time. There would be one customer out and we'd go and check it. And then there was a bit of logic that they had, they didn't tell us about.
So we had to add that rule and somehow we just got into this loop where. We always won customer out and it was always for a different reason, but the cost of doing that manual reconciliation was horrendous. Data match allowed me to go, I can run that really quick. We grab the Excel data, I'd upload it, just dump it in like we do, get a new tile, compare it to the numbers we were producing consistently, and it would then highlight the one record that was out, you know.
Very short amount of time, and then I could spend all the time trying to work with them about why they had this record that we didn't. Or vice versa. So yeah, it just again, took something that was many hours of frustration and made up minutes, which was great. The idea of layering those rules though, that's important because otherwise you're just gonna brute force two very large tables.
Match everything and that is gonna cost you a shit ton of compute, a shit ton of credits, a shit ton of tokens depending on how your cloud analytics database vendor is charging you for that compute.
Nigel: Yeah, so we poked a couple of reasonably well known open source libraries when we first started, 'cause we're like, we're not gonna reinvent the wheel.
This seems to be a fairly solved thing. Surely there's just gonna be a package we can pull down, point it to two tables and hit go. And that's, and we will run it. Technically there are, and we did start with one and it did work. Where we tend to run into, where we ran into rolls was it needed quite a lot of configuration, so we effectively had to come up with a whole wrap to pass it, enough configuration to make it work.
And that was fine. That was more just a bit of app development to give it what it needs. But then some of the problem was, it was, as is usually the case, it had been developed to run. On a particular database, I think it was Postgres from memory, which is quite common, or was MySQL. So it was heavily skewed towards a row storage database and how row storage databases work.
And so it was optimized. So the queries. So the queries when we came to run them on BigQuery, they ran and that was fine, but we didn't really get any. The benefits of BigQuery being a column and database and partition pruning and the like. So we played with it and played with it, and it got closer and closer.
In the end, we thought actually it'd be just quicker to write a template that would run a BigQuery and we'll effectively do the same thing, but we'll make a template and make it. Specific BigQuery. And we did, and that's effectively where we got to so we can optimize what we give to BigQuery. So it's very efficient and it runs very quickly and it doesn't really cost us anything.
'cause we know where the performance and cost savings are with BigQuery and that's how we got to our Pattern. We effectively just took an open source, one found the strengths and weaknesses. Rolled a variant of it, uh, for us, for BigQuery.
Shane: And I think the other thing is we only run this when we need to. So it's not baked in as a core trust rule for every movement of data through every layer for every tile.
Is it?
Nigel: No. This is effectively an exception thing. This is when something goes wrong. This is somewhere where we can quickly go click and say, ah, there's 10 customers that aren't. Aren't in this table where we'd expect them to be. So it's a really quick way without having to regress to and go and customize something because it already has all the tiles and a catalog loaded.
You can just go pick tile A, pick tile B, compare them, show me the differences, uh, and go away. So it takes the first layer of context and the overhead, sorry, of thinking about it gives you your answer in a report. Then you can go and do, as you said, do the analysis. 'cause now I've got a list of customer IDs that haven't flowed.
I can grab one of those customer IDs and actually go specifically look for it. And that's a really quite simple proposition because that nicely flows onto some of the other features we've built around looking, tracing values.
Shane: I remember when we did that data migration use case, remember, where we grabbed data from a legacy source system and then pushed it through us, and then made it available as a API so that the new vendor could migrate the old data into the new platform.
And we had that gentleman's agreement, which was we do all the logic to match the new business rules for the new system. So effectively they'd hit the API for the data, grab the data, load it straight into their system, and there'll be no transformations between those steps. So that we always knew when we needed to change the way the data looked, it sat with us.
And when we did that test run and all of a sudden, let's say customer again, we passed. A hundred thousand customers out and only 80,000 turned up in their system. And we spent all that time manually trying to figure out why. And actually the answer was they had done some changes on their side between getting the data and loading it through their APIs, even though they said they wouldn't.
If I had just been able to take the final result that they'd loaded from their system and back flushed it in as a tile and then said, compare, that would've told me exactly which records didn't make it. And then yes, I would still have to talk to 'em about how come they didn't make it. But again, that would've saved hours if not days of proving we send a hundred thousand, you loaded 80.
We know. Therefore, it's somewhere between those steps and it's nothing to do with. Everything to the left of us would've saved us time. If we had to build it back then.
Nigel: Yeah, it's, that's why, I guess it's in the app, it's what I would call a support feature. It's something we don't use very often, but if we need to, it's there to quickly do something and we don't have to remember how do I data diff, what queries do I need to run?
Grab out some queries, change the table names and the key names in them to run them. Again, it's click, click, here's my report. You know, it's a small overhead, but. When you're trying to do a whole lot of things. Yeah. That you're grateful for it.
Shane: Yep. Hours to minutes. That's what I care about. Yep.
Nigel: Excellent.
Shane: Alright. I hope everybody has a simply magical day.