
Merging Data Vault and Medallion Architecture Patterns with Patrick Cuba
AgileData Podcast #58
Join Shane Gibson as he chats with Patrick Cuba on combining the Data Vault data modeling pattern with the Medallion Architecture pattern.
This discussion was based on the patterns described in this article:
https://medium.com/the-modern-scientist/the-modern-data-vault-stack-75103102e3d2
Listen
Listen on all good podcast hosts or over at:
Read
Read the podcast transcript at:
https://agiledata.io/podcast/agiledata-podcast/merging-data-vault-and-medallion-architecture-patterns-with-patrick-cuba/#read
Google NoteBookLLM Briefing
Briefing Document: Merging Data Vault and Medallion Architecture
1. Introduction
This document summarises the key points from a podcast discussion between Patrick Cuba and Shane Gibson, exploring the intersection of Data Vault modelling and Medallion Architecture patterns. The conversation delves into their practical experiences, challenges, and evolving perspectives on data modelling and architecture in the modern data landscape. They unpack the two main ideas and how they fit together.
2. Background and Experience
Patrick Cuba: Has a background as a "hardcore SAS architect," encountering Data Vault at a customer site in Brisbane. He recognized the potential for automation and developed a tool to generate Data Vault models. He's worked with various Data Vault implementations, including NoSQL platforms and tools like Warescape, and now works at Snowflake, focusing on customer onboarding and the practical application of Data Vault.
"my background is I was a hardcore SAS architect... And I actually came across Data Vault at a customer site."
"I was not intending to do any data vault work because it was about, getting customers on boarded onto Snowflake."
Shane Gibson: Also has experience in SAS, and finds it intriguing that Brisbane is an origin point for Data Vault adoption in Australasia. He's particularly interested in Data Vault's modelling patterns, as well as the way you build things around it. He advocates for a flexible approach, combining Data Vault with other modelling techniques like One Big Table and Activity Schema. He has a product using "landing history, design and consume" as it's layering concepts.
3. Data Vault Defined
Enterprise Vision: Patrick highlights Dan Linstedt's definition of Data Vault as "a system of business intelligence containing the necessary components needed to accomplish enterprise vision in data warehousing and information delivery." He emphasizes the "enterprise vision" as a key aspect, asking, "what are we actually doing with this data model?"
Core Components: The core of a data model, according to Patrick, must address:
Business entities
Relationships between entities (interactions, transactions, etc.)
State information of entities. These are then mapped to hubs, links and satellites in the vault.
Platform Advantage: Patrick believes Data Vault is advantageous because "nothing in the industry takes advantage of the OLAP platform’s capabilities quite like Data Vault does," as it embodies those three things.
Integration: Data Vault excels at integrating data by business keys, allowing non-destructive ingestion as data sources change. The data vault "is designed to ingest those non destructively."
Flexibility: Patrick acknowledges that Data Vault isn't always the best fit, stating, "looking at your use case, I think the complexity is not worth it. You should stick to Kimball modeling." He notes the need for a nuanced approach, depending on complexity.
4. Medallion Architecture Defined
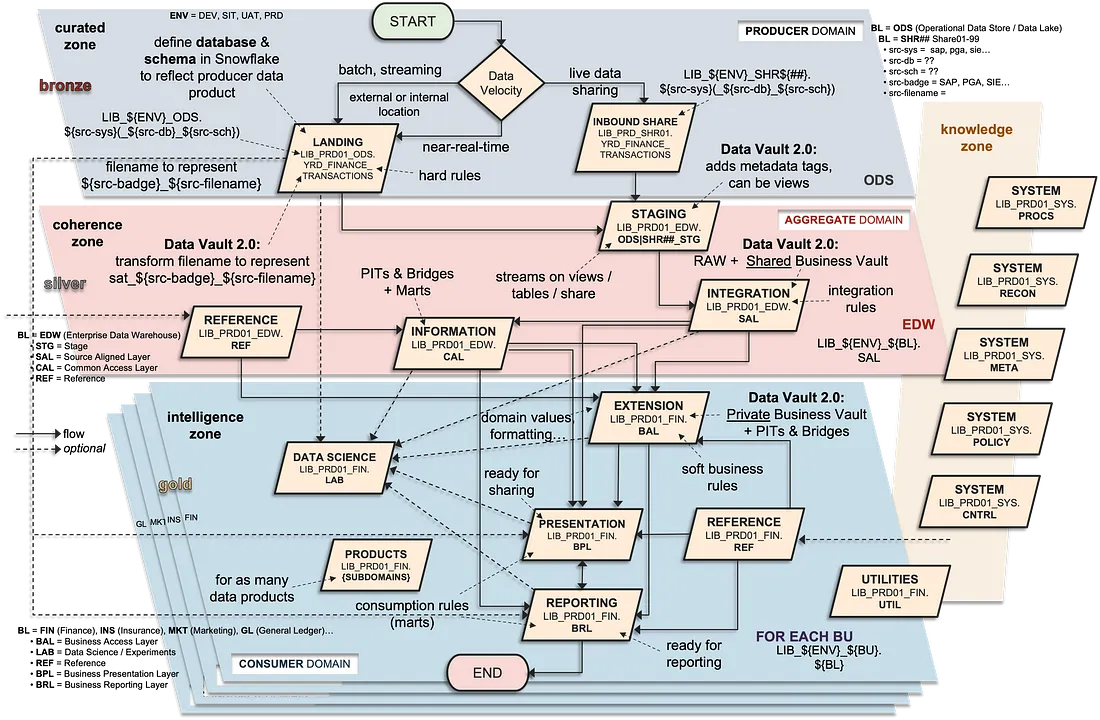
Layered Approach: Patrick views Medallion Architecture as a "layered architecture" that's been around for a while but has been well-marketed. It involves landing, transforming, and presenting data, and he notes that many businesses have similar processes but use different terms. The layers, as he and others have used, have names such as "curated zone, coherent zone and intelligent zone", or "cell, EDW, and consumption layer".
Layered Principle: Shane sees it as a way to "set a bunch of principles. Policies or patterns to say, this is going to happen in this layer". It’s all about putting data into well-defined layers based on how it's used, rather than just a giant bucket. It's about code layers, not physical layers.
Consistent Purpose: The goal of layering is to avoid a "big bucket of crap that we can’t deal with." The various terms over time include "persisting staging area, EDW, retail presentation". It is important to be clear what the purpose of a given layer is.
Bronze, Silver, Gold Mapping: They discuss the mapping of layers:
Bronze: Is like an ODS (Operational Data Store), or source-aligned data (or a "landing history")
Silver: Represents the EDW (Enterprise Data Warehouse) layer, where data is designed, conformed and integrated. This is where Data Vault lives. (Or the "design" layer).
Gold: A consumer or presentation layer, tailored for specific uses. (Or the "consume" layer).
Beyond Names: Different organisations will give the layers different names. Patrick has seen "curated, coherent and intelligent zone" or "cell, source-aligned and integration layer", "design" and "consumption" layer.
Iterative: Patrick notes his architectures are iterative, evolving with customer needs and clever ideas they have. He always works with clever people who know what they want. He often uses whiteboarding with customers to get everyone in the room to discuss what to use. His libraries are labelled "lib_" and this comes from working with a scientist who thought it useful to label them all as libraries, due to his SAS experience.
5. Merging Data Vault and Medallion Architecture
Data Vault in Silver: Patrick positions the Data Vault modelling technique (hubs, links, satellites) within the silver (or coherent) layer. He sees the core modeling technique for Vault as fitting here.
Persistent Staging vs Raw Vault: Patrick emphasizes the distinction between a persistent staging area (bronze) and the raw vault in silver.
Bronze: mirrors the source system as much as possible. The physical tables mirror the source.
Raw Vault: is where conformed Hubs, Links and Satellites live.
Raw Vault: Hubs, Links and Satellites in Data Vault 2.0 reflect the source, with changes structured into change tracking. Satellites only track true changes. Links depict business processes from source. Hubs are the pins that hold a data platform together.
Not all data in the landing zone is equal, so it makes sense to split it out. It is easy to purge or archive data in the bronze area if required.
Business Vault: Patrick advocates for a "sparsely modeled" business vault. Where you transform data not available in the source, and add intelligence to the Data Vault, "you simply expand it with sat underscore bv underscore whatever with those persisted attributes from that business rule that you’ve developed."
Data Auditing: The business vault inherits the same auditability as the rest of the raw vault. He thinks the identifiers should be split into it's own satellite table for easier GDPR management. Instead of deleting, you should scrub the data to protect it, but keep the hash div, so you know when it turns up again.
Complexity Location: They discuss where to solve complex issues (mapping keys, etc). Patrick recommends solving them earlier in the process (source, pre-staging, business vault) rather than leaving it to users (the "wooden spoon" option). The earlier you solve it, the cheaper it will be, and the simpler your business terms will become.
Source Specific Vaults: Where you have customer keys in different systems, the decision must be made on where to do the key conformity. Do we conform in bronze? (No, says Shane). You can choose whether to have source-specific hubs to begin with or conform the keys to a single hub straight away. Conforming hub is good practice.
Business Vault (again): Good practice means that raw holds the data, then create additional Business Vault objects where we need to infer, conform or do "bad things" to it to make it fit for purpose. Patrick notes that Business Vault should be as small as possible, a perfect world would have no need of a business vault. Should you copy raw data to business vault? This should not be done unless there is a good reason to do so. Everything in business vault should be declarative and item potent. You also should think about "separation of business rules and outcomes" so that you can write business logic in any language you want.
6. Patterns, Principles, and Policies
Patterns: Reusable solutions to common problems.
Principles: Fundamental beliefs (e.g., "avoid duplication at all costs"), acting as guides that might not always be followed.
"Ideally we want to virtualise the business vault as much as possible"
Policies: Enforceable rules (e.g., data stored in BRONZE must match the source system). Breaking a policy will cause you problems.
The data stored in BRONZE must match the source system
Computational Governance: Ideally you want code that tells you when a policy has been broken. "Write some code which is useful anyway to say check the schema of that table in bronze, check the schema of the table we got given if they don’t match, somebody’s inferring, conforming, doing bad shit in there, flag it".
Renaming: Should be done only as few times as possible, but the place to do that is not always clear. You might need it for the tooling or a logical or business view. It's better to use views in the Gold area for this purpose. There is an anti-corruption layer in the Silver layer to add column names to columns (but not physically) in order to conform, but this doesn't mean that the column name is changed in the source.
Data Quality: This is another core engineering practice, applied in multiple different places. There needs to be a collection of data quality patterns that are usable throughout the different layers.
Metrics: Includes facts, measures and metrics. They must be carefully considered where to do it.
Facts: A number that comes from a system (quantity)
Measures: Things we do to facts (sum, average, count)
Metrics: formulas, excel like A divided by B, inferring something based on facts or measures.
Metric Vault: Can be a place to put metrics for consumption later on (business vault extension).
Virtual vs Physical: When using views for business rules, you should consider if you want the data to be historical or not, and this will help you to decide whether to virtualise or persist. Sometimes you need to materialise your view for performance and that is ok. It might be a principle to use virtual business rules as much as possible.
Code Reuse: DataVault helps to write small blocks of reusable code (like YAML).
Master Concepts: The core concepts such as customer, supplier and employee need to be mastered. These can sometimes be weak (invoice status, admin processes) or master concepts. Master concepts should be managed once and reused everywhere.
7. Semantic Language and Analogies
Context is Key: The language and terminology of data work are important for communication and clarity. You need to think about how you refer to different elements (landing, producer, intelligence, consumer) as these are often swapped around, or have different meanings in different contexts. Data people understand this, but others new to the field may struggle.
Standardization: Standardizing language is important when discussing patterns, along with analogies.
Kitchen Analogy: Shane uses a kitchen analogy, where you have a storeroom, kitchen (where work happens) and a server where data is consumed.
8. Further Considerations
Batch and Streaming: How these happen within the architecture was not explored too deeply, but this was also identified as a lens to view the topic.
Medium Articles: Patrick publishes primarily on Medium.
Technical Book: Patrick has a book on Amazon on how to technically implement Data Vault. There are lots of books on how to model it but less on implementing it.
9. Conclusion
The discussion highlights the need for a balanced and pragmatic approach to data architecture, combining the principles of Data Vault modeling with the flexibility of a Medallion architecture. Both Patrick and Shane encourage clear articulation of patterns, principles, and policies to guide decision-making. Their ideas are focused on creating robust, scalable data solutions.