
Redesigning traditional data systems to support Large Language Models and AI agents with Mayowa Oludoyi
AgileData Podcast #80
Join Shane Gibson as he chats with Mayowa Oludoyi about redesigning traditional data systems to better support LLM and AI Agents
Listen
Listen on all good podcast hosts or over at:
Subscribe: Apple Podcast | Spotify | Google Podcast | Amazon Audible | TuneIn | iHeartRadio | PlayerFM | Listen Notes | Podchaser | Deezer | Podcast Addict |
You can get in touch with Mayowa via LinkedIn
Tired of vague data requests and endless requirement meetings? The Information Product Canvas helps you get clarity in 30 minutes or less?
Google NotebookLM Mindmap
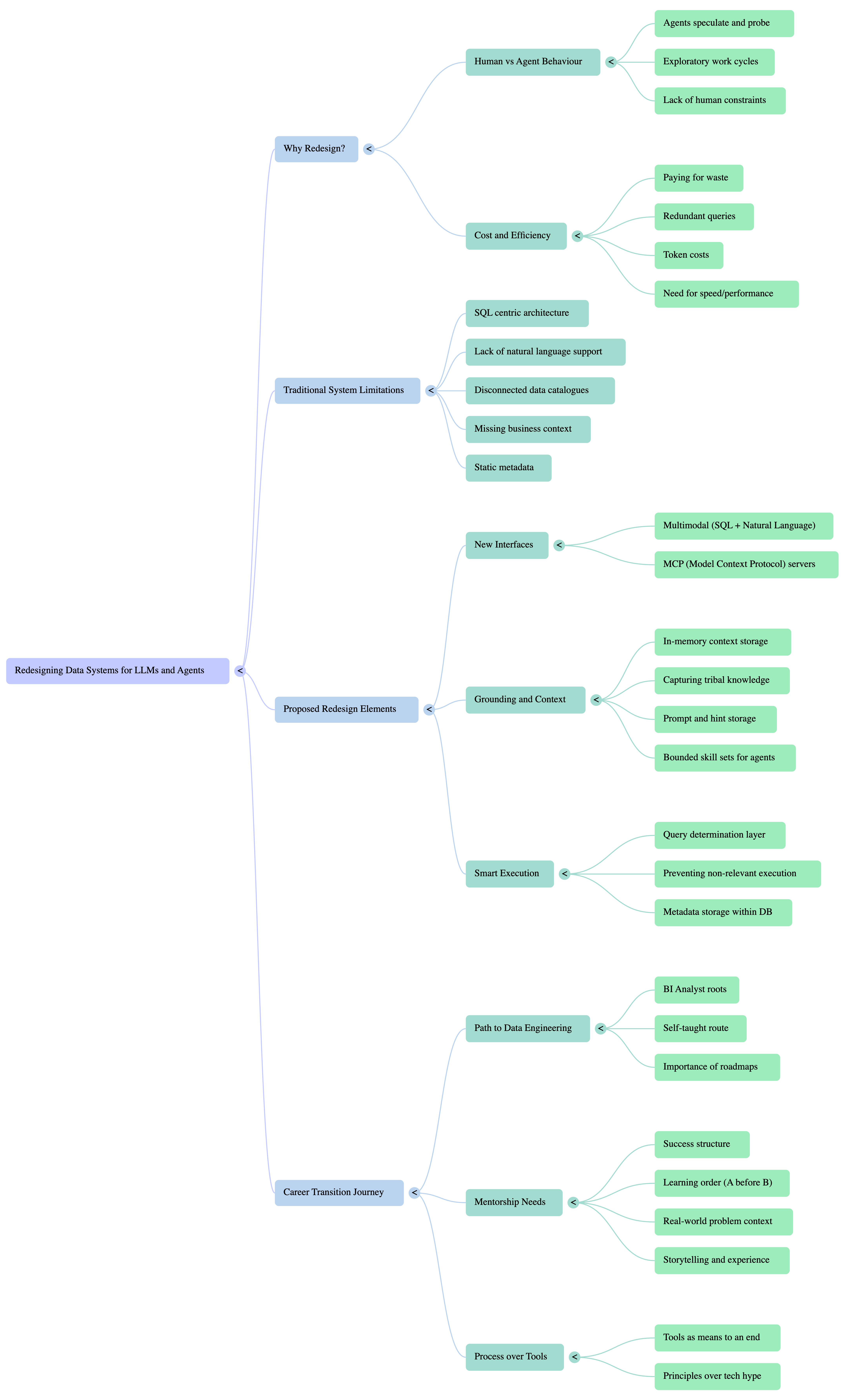
Google NoteBookLM Briefing
Executive Summary
To effectively harness the business value of Large Language Models (LLMs) and AI agents, enterprises must fundamentally redesign their data systems. The current paradigm, built for direct human interaction via structured queries, is ill-suited for the speculative and exploratory nature of AI agents, leading to significant inefficiency, waste, and prohibitive costs. Agents do not simply query data; they “probe” and investigate, a process that generates redundant queries and consumes vast resources if left unmanaged.
A paradigm shift is required, moving toward an architecture that is inherently AI-friendly. This involves three core transformations:
Developing Multimodal Query Interfaces: Systems must evolve beyond SQL-only interaction to support both structured queries and natural language, providing the rich, multimodal communication channel that agents require.
Integrating Context as a First-Class Citizen: The historical separation of data and its descriptive context must end. Future systems need to store and surface rich metadata, business definitions, and operational knowledge directly alongside the data, providing the essential “grounding” that agents need to perform accurately and efficiently.
Implementing Intelligent Query Management: Data platforms must become active participants in the query process, capable of determining which agent-generated probes are necessary and which are wasteful, thereby preventing redundant execution and controlling costs.
This briefing document synthesizes these critical insights, outlining the limitations of traditional systems and presenting a blueprint for the next generation of data architecture designed to convert AI’s speculative power into tangible business speed and value.
1. The Imperative for Change: From BI to Foundational Data Engineering
The evolution of data roles provides a crucial lens for understanding the need for architectural change. The journey of Mayowa Oludoyi from a Business Intelligence (BI) Analyst to a Data Engineer highlights a critical realization: the ultimate value of any data product, be it a dashboard or a machine learning model, is contingent upon the quality and structure of the underlying data.
Motivation for the Shift: The transition was prompted by the understanding that “everything still come back to the data.” A significant portion of time in analytics and machine learning is spent on transforming and cleaning data, suggesting that more focus should be placed on the foundational data processes rather than solely on the end product.
Challenges in Skill Acquisition: This career transition was not a straightforward path. The primary difficulties encountered were:
Lack of Mentorship: Finding a mentor to provide structured guidance—explaining the “why” behind learning paths and the nature of real-world problems—proved difficult. Most learning had to be self-directed through courses and books.
Absence of a Structured Curriculum: Initial learning was described as “a little bit scattered” due to the lack of clear, process-oriented roadmaps. While tool-focused roadmaps (Spark, DBT, etc.) exist, the more valuable curricula focus on fundamental processes and principles, as “tools we always change... it is a means to an end.”
The Value of Mentorship: A valuable mentor is not one who teaches coding, but one who provides structure and context. This includes explaining the types of problems data engineering solves, the reasons for solving them, and the logical sequence of learning (”you need to learn A, before you learn B”). This contextual understanding is often missing from online courses and is essential for career progression.
2. The Core Problem: Why Traditional Data Systems Fail AI Agents
The central argument for redesigning data systems is that they were built for a different user: a human executing precise, structured commands. AI agents interact with data in a fundamentally different manner, and this mismatch creates significant friction and waste.
Defining the “Traditional Data System”
For this analysis, a traditional data system is one where the primary interaction model involves a user leveraging a structured language (e.g., SQL) to execute a query against a database (e.g., Postgres) and receive a direct result.
The Nature of AI Agents vs. Humans
The key distinction lies in the method of inquiry. Humans query, but agents investigate.
Speculation and Exploration: Unlike a human who formulates a specific SQL statement, an agent must often “speculate” to find an answer. It performs exploratory work, probing the data system with a series of queries to build understanding. This process is inherently iterative and less direct.
Probing vs. Querying: The interaction is better described as “probing” rather than querying. The agent is investigating the data landscape, which is fundamentally different from a human retrieving a known piece of information. As stated in the discussion, “agents don’t just query, they probe.”
The Consequence of Misalignment: Waste and Inefficiency
Simply layering an AI agent on top of a traditional data system introduces massive inefficiencies that businesses cannot afford.
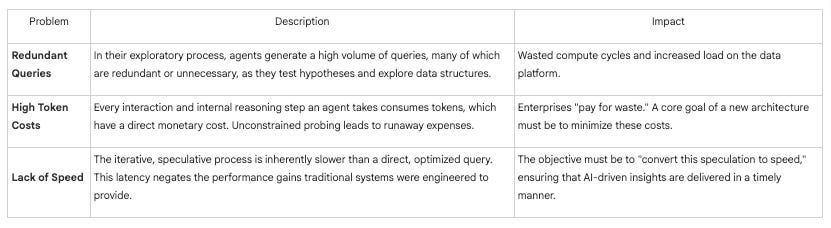
The Context Gap
Traditional systems are designed to store data, not the rich context surrounding it. Agents, however, are critically dependent on this context for “grounding”—the ability to understand the data’s meaning, relevance, and structure. While data catalogs have historically attempted to solve this, they often failed due to the high manual effort required to populate them. With AI, this descriptive, natural language context is no longer a “nice-to-have” but a core requirement for system performance and accuracy.
3. Architecting the Future: A Blueprint for AI-Ready Data Systems
To address these shortcomings, a new architectural approach is necessary. This approach redefines the interface, integrates context as a core component, and introduces intelligent oversight of the query process.
3.1. A New Multimodal Query Interface
The first step is to create a different query interface that serves both humans and machines effectively. This interface must be multimodal, accommodating both:
Structured Query Language (e.g., SQL): For precise, efficient data retrieval.
Natural Language: To allow agents to process and leverage the rich descriptive context needed for grounding and reasoning.
This dual capability allows the system to support traditional analytics while simultaneously providing the necessary foundation for advanced agent-based interactions.
3.2. Integrated Context as a First-Class Citizen
Context must be elevated from an afterthought in a separate catalog to an integrated component of the data platform. This can be achieved by providing agents with access to various forms of grounding material:
Past Queries and Code: Providing an LLM with a repository of previously written, successful SQL queries serves as powerful, practical context. Mayowa noted this technique works “perfectly” for his personal use, allowing the LLM to generate new queries based on established patterns.
Code with Embedded Explanations: The most effective context combines structured code with natural language explanations. In one example, an agent’s performance improved dramatically when it was given access not only to a repository of transformation rules (code) but also to comments within that code explaining why each rule was created and what business purpose it served. This provides both the “how” (the code) and the “why” (the context).
Centralized Context Stores: The system architecture must include a mechanism, potentially a “meta store” or a new function within the database itself, to store and serve this context universally. This ensures that any agent interacting with the system has access to the same grounding information, promoting consistency and accuracy.
3.3. Intelligent Query Management
To combat waste, the data system must evolve from a passive recipient of queries to an active manager of them. The system itself should have the intelligence to “determine what query or probe needs to be executed.” By leveraging its own metadata, the system can identify and prevent the execution of irrelevant or redundant queries generated by an agent’s speculative process, thereby preserving resources and controlling costs.
3.4. The Rise of Specialised Agents
An effective strategy for managing complexity and improving results is to move away from a single, generalist agent. Instead, a team of specialized agents, each with a “bounded context,” can be deployed. For instance:
An “ADI the data modeler” agent focuses solely on data modeling tasks and is given context specific to that domain.
An “ADI the engineer” agent handles data transformation rules.
An “ADI de boss” agent orchestrates the workflow, passing tasks to the appropriate specialist agent.
This approach mirrors how human expert teams function and has been shown to produce significantly better and more reliable results by ensuring each agent operates within a well-defined and deeply contextualized skill set.
Tired of vague data requests and endless requirement meetings? The Information Product Canvas helps you get clarity in 30 minutes or less?
Transcript
Shane: Welcome to the Agile Data Podcast. I’m Shane Gibson.
Mayowa: Hi, this is Mayowa joining from Nigeria.
Shane: Thanks for coming on the show. Today we’re gonna talk about redesigning current data systems to power LMS and agents. But before we do that, why don’t you give the audience a bit of background about yourself.
Mayowa: thank you once again. Again, let me just say thank you for bringing me to the podcast and , like I mentioned earlier, my name is Maya . I started off my career working as a business intelligence analyst. And honestly, I still feel it’s still one of the most interesting roles and anybody , can, get involved in. It’s very interesting. And while working as a business intelligence analyst, this kind of gave me the opportunity to work several projects. I started off working in consulting and so that kind of gave me the opportunity to work on, several projects.
We have clients working in telecommunication, in banking, in health tech. And so , starting off that way, give me, enough opportunity to experience, different projects. And while working, I had the opportunity to working on several projects, like working on data warehousing, building data reporting, power bi, Tableau and all of those interesting data projects. But then as time goes on, I move on to. A new company after two years. And then in this new company, it is just basically a payment company that is in FinTech. And then, , while I was there, I did a lot of work around analytics, data engineering, and that was where my interest in de engineering started, evolving, and from there I left the company another after two years, and then I moved into a bank. And then this time around I started working as a data engineer. And why, working as a data engineer, as a bank have a lot of legacy system. There’s a lot of things, a lot of moving parts when it comes to data engineering in a bank. You talk about privacy, you talk about, building systems that are highly protected, all of those things.
So while in the bank I started, having this interest in. how to actually build, robust pipelines. So I wanted to move from the normal, building ETL. And so I started learning and that was how my career has, spiraled all through the years. And yeah.
Here we are today.
Shane: that moved from being a business intelligence analyst focusing on the reporting. Tablet, power bi, I’m assuming the data was served to you, so you grabbed the data you needed and you focused on visualization and user experience,
And then moving back into the engineering side, into the code to transforms the data, collects it, all that kind of gnarly stuff that, that’s a common path for people.
How did you find it? How did you find changing from, a set of tools and a certain, set of skills to then expanding them out into new tools and new skills? Was that an easy journey or did you find that step change quite difficult.
Mayowa: I’ll say for me it was not that easy journey. The reason being that the resources are there on online, most time the resources are not what translates to business value, right? So sometimes you have to struggle to get things done. So it was not an easy journey. But one thing that I feel prompted this shift in me was that at the end of the day I discovered that one of the most important process still remains the data. You can have beautiful dashboard, you can have machine learning models that are doing, fantastic. But everything still come back to the data. So I started asking myself the question, . I think I spend a lot of time, transforming data, cleaning data, whether to produce report or to do machine learning. And so I feel like it’s important to spend a lot of time around the data itself than even the product. I mean, The end product is really important, Because that is the whole point. But then I feel like it’s important to spend more time on Iran. So that was what prompted, but then I had to, look for a way to attend conferences, take courses online, and then that shift was not easy.
But, gradually I started building all the necessary experience that I need. Yeah.
Shane: And so often I’ll see people that make that change from being a, bi centric set of skills to that data engineering set of skills. Often they’re in an organization that actually encourages that change. So they’re in an organization, they’ve got a bunch of mentors, a bunch of people who’ve done it before and they can get a lot of help and mentoring about the things they need to learn and a lot of feedback.
In some organizations that’s not possible. So people will go and study on the site, they’ll go and find courses and they’ll try and learn it to help them then, effectively change organizations to change roles. Which way did you go? Did you find that you had mentoring and support within an organization to do the step change?
Or did you have to learn outside the organization you’re in and then change jobs to, to go into the new role?
Mayowa: honestly I couldn’t find a mentor. I had to take the other route. I went all out to, get information. I have a couple of people who, tell me exactly, oh, this is what you need to do. You can take this course. I have those people, I have people tell me that, but I didn’t have the opportunity of having someone. Who will hold my hand through the rubies and show me everything I need to know. So most of the time I had to go out there myself, pick up courses, pick up books to read and that was it. So that was the part that I took. But I understand what you’re saying. There are a lot of people who have the opportunity of having senior data engineer on the team who can tell them what to do, and then they learn through, working on different tasks, different projects along the, but I didn’t have the opportunity.
Shane: And if we think about the idea of a curriculum, an idea of these types of courses, these types of tools, these types of skills and learning them potentially in this order makes sense, so almost like a manifest or a curriculum of what you might want to do, rather than having to try and find it all yourself.
Did you find that, did you find that there were resources out there that gave you the idea of a bootcamp? Or did you have to go and talk to lots of people and cobble it together to yourself to figure out how you went through that path?
Mayowa: basically, my knowledge was a little bit scattered at the very start because there was no tailored curriculum to give me more a roadmap. These days I see a lot of roadmaps here and there, and I wish I had this when I was starting, right? But then when I start, when I started, I didn’t have this roadmap.
I had to learn. So at the end of the day, I have, a lot of knowledge and it took a lot of time, a lot of, learning to put everything together to make sense actually. But I think that problem has been solved. I think I’ve seen a lot of resources online, a lot of roadmaps that I think is doing justice to that now.
yeah. And those roadmaps, are they primarily technical and tool-based, or are they about the process and the ways of working as much as they are about the technologies? Because again, when I see, if I look at job ads or I look at what people say they do, I’ll hear DBT Spark, Databricks, I hear tools and technology versus the skills and the tasks that, you need technology to deliver them, but they’re just as important as the technology itself.
Shane: So what did you find?
Mayowa: I can share this with you at the end of the, session because I don’t wanna mention names. there’s this particular roadmap that I’ve seen, which I think is very good. When you look at the roadmap, they didn’t spend a lot of time talking about tools.
Tools can change, but they spend a lot of time around processes, which I think is really great. Things, fundamentals that I think everybody should know when it comes to data engineering. And even though that domain I think is really good. And I shared the same. Opinion. I see a lot of roadmaps where they talk about, spark DBTI, I don’t think that is the best. I think it’s because tools we always change. They are, tools are like, it is a means to an end. It’s not an end in itself. So I feel like roadmap that talks about the real process, the real principles.
I think they’re very great and I think that is what we help a lot of people to, to move up quickly. .
Shane: We met each other on the practical data community and it’s still one of my most, my favorite, most active communities I’m in. And yeah, I think something, something we should look to do is creating that roadmap or that curriculum as an open source roadmap and curriculum as part of that community, because lots of people have that struggle when they’re trying to get into the domain or drop a jump across the roles.
Where do you start? And so last question before we get onto the current data stuff because this whole onboarding of a person into a new career really intrigues me. So when you talk about, if you had have found a mentor who would’ve helped you through that process.
What would you have expected them to do with you? What would you want them to help with?
Mayowa: Sorry, can you repeat that again?
Shane: So you talked about the fact that, you were looking for a mentor and you struggled to find one.
Say you had found one, let’s say somebody had said, yep. Happy to help you take that next step in your journey. What would’ve been valuable for that mentor to do? What would you expect them to actually do to help you progress your career?
Mayowa: I think one major thing I look out for in a mentor, it’s not to. Teach me maybe how to write code, but rather just to show me exactly what I need to succeed and I’ll explain what I mean. So for example when I was trying to, break into data engineering, it was difficult to actually see somebody who have the experience of what happens in data engineering. There is a lot of resources on how to write SQL Python and all those things, right? But I need somebody who work in data engineering who tells me, this is the kind of problem we solve. This is why we need to solve this problem. This is why you need to learn for, that kind of structure. that is what I’m looking for, and don’t think it’s something that is readily available. In the market, or I’m not even sure. Most courses offer that even when they, offer these courses, online. So I think for me personally, I’m looking for in a mentor, somebody who is not just interested in, learn these skills, but tell you exactly the structure of learning. All right? This is important. For example, you need to learn A, before you learn. B, you need to learn B before you learn C, something like that. That is what I’m looking for in a mentor.
Shane: I think that’s the important part. I, so I mentor people every now and again, and I know a bunch of people that want to mentor but aren’t sure what the process is. And they often think it is more teaching. They think they’re gonna have to spend hours teaching somebody how to do something. And if you’re in an organization where you are mentoring somebody in your team, junior, then yes you probably will do that.
But if you are external to that organization, to that person, to me it’s about connecting with somebody, listening to where they’re at. Potentially making a suggestion what they might want to try next and why it’s about storytelling, one of the things I find is if you can tell a story from your career that I did this and this is what happened and this is why it happened, that’s valuable.
And then the last one is context. When somebody says, okay, why does everybody say you shouldn’t do real time streaming? The context is, it’s expensive still to do that versus batch nine Times outta 10, they don’t need the data straight away. They can live with 15 minutes or an hour. So everybody says they want it, but actually when they see the cost of it, they say they don’t.
That’s the context. And you tend not to find that story of the context of why does everybody say don’t do near real time? Unless you have to have, it is not well written somewhere. And it’s definitely I don’t often see it as part of the course, so Yeah. I’m with you.
Is it really is an hour, maybe to a week having a chat with somebody and just helping them with their career. And so for me I think about all the people that helped me, all the people that helped mentored me and my career, , I think people who have been doing it for a while need to pay it back.
So anyway end of end of pitch for people to mentor more people in the world. Okay. So let’s talk about this idea of redesigning the current data systems to make them better for LMS and ai. So when you kind of propose that as a subject, talk me through it. What do you mean by that?
Mayowa: I started thinking about the whole LLM. Thing some few months back. As a matter of fact just like I told you, I have a, an article I want to release, which I think I just wanted to talk about, the traditional data systems and what we need to get to that point where enterprise can take advantage of what LLM is offering right now. And this started off from, working and everybody’s talking about LLM, since 2023 and now everybody has been talking about LLM and the whole boss, and there’s so much, happening LLM these days. So I ask myself on the job right now, I use charge GPT, I use Claude for a lot of things, but I ask myself, how does the enterprise, how does the business still get value from these LMS at the end of the day? So that was all led to that thinking. And then I started exploring and I’ve seen very great articles and, research papers around that. So for me, the management team here or where I work, they’re not just interested in hype, they’re interested in value, so before they put money into any of these things, they want to know how much value they can get from it.
So sometimes it’s difficult to get a buy-in the management about, some of these things unless they see, what they can get from it. So that was why I started talking about, I started thinking about how we can, bring value to the enterprise through early. But I then I discovered that. the current system. I don’t think that value can be created immediately with the current systems that we have, if at all. There’s gonna be a value. When I say value I’m not saying, we’ve seen agenda doing interesting things like, a lot of people integrate agent to their GitHub repository.
that is good for the developer, but when it comes to the business, I don’t think there’s so much value that they’re getting from that. So I think for us to get to that point, there’s gonna be a need for us to rethink some of the processes and even the data system itself should, so that, that was how I got to that topic, to that theme that I gave you.
Yeah.
Shane: Okay and so there’s a couple way we can approach this. We can look at what you would see as a traditional data system And describe that, and then figure out what you think should change, or we could just. Identify some things, people, processes, technology design that you think when you look at that, that needs to change for the use of LMS and to add value back to stakeholders.
So I’m with you. We see lots of use cases of developers using copilots and LMS to automate or make their jobs easier, remove that drossy work. We see, some interesting use cases using those tools to automate business processes
Data. And then there’s this third. Kind of dimension, which is agents using data for stakeholders.
It’s not business process automation, and it’s not co-pilots for developers. And
Now everybody goes, oh, it’s text to sql, right? Ask a question get an answer. That’s the obvious use case. So which way do you wanna do it? Do you wanna describe a legacy system? And then what your change, or do you want to talk about specific use cases that you think are valuable to a stakeholder?
And then we talk about it from that lens.
Mayowa: I think we talk, we can talk about a bit of the two, when I was, trying to, just put some point together before joining I actually have three questions. I feel like it’s important for us to answer.
One of the most important questions is why do we need to redesign the data system? Why is that we can’t take advantage of the current system? I’m talking about the traditional systems, right? I think that is very important and then. We then need to answer the question, why can’t the current system be leveraged as it Because there are two different things. One thing is that we need to answer the question why we need to redesign the data system. We need to talk about why can’t the current system be used as it is? Unless even, maybe we can even add on top of that. what do the traditional data system looks like?
Maybe somebody’s listening to this conversation and does not even know what the traditional data system looks like. So we might even want to touch about that. And I think the final question that I think we should try to provide an answer to is how then do we redesign the, system that we feel or that we think will be able to get us to that level where we can, get massive gain from LMS and agents.
Shane: let’s do that. One of the things that we need to always recognize is we need to anchor our language in a way that everybody else gets a shared language. That we are using. So when you say traditional data system, I have in my head what I think a traditional data system is, and it’s probably not the same as yours.
Because mine’s based on, 30 years ago, 20 years ago, 10 years ago, there’s been, broad iterations of traditional data systems. What I always suggest people do right, is when they’re, they’ve got a mental picture in their head, they’ve got a map. It’s always useful to describe the map.
In a way that everybody goes, oh, that’s what you mean. But let’s start off, what do you wanna do? Do you wanna do, why do we need to redesign traditional data systems? Or why can’t we leverage them for lms? Take me away.
Mayowa: I think we should start with the why, we designed the data system. I think one thing that is really important is that we need to know that LLMs or agent, whichever way you want to call it, they’re different from humans, right? if you have used agents or if you’ve used LLMs, but whether it’s strategy or clo, whichever one, and then you use it around, data, you will know that they don’t ask once, they don’t ask once and then analyze. There might be a need for you to, ask again, change some things. And so because of that, an attempt for these agents or LLM to provide an answer they speculate. That means they try to do some form of exploratory work, so that makes them different from human.
So because they’re depending on whatever it is that you give to them, for them to now, think. So that in itself tells you immediately that they behave deriving from humans. And so it is the natural way we get information from data system cannot be the same way that these agents get, information for us.
I don’t know if that makes sense.
Shane: Yeah, so let me just play it back and see if I understand
What you’re saying. So if we look at the lms, the foundational models, they’ve been trained on large knowledge bases of text.
And so the early days, we’d ask ‘em a question, they would search that knowledge base and they’d come back with an answer.
And all we did was we’d ask a question, it would look into itself like a human would if it only could look at its memory. So it would go what do I know about that? Here’s an answer. And then what we found was actually we wanna provide context to it. We wanna provide some additional information that foundational model may not have or may not have brought to the front of its memory.
And so we started seeing techniques like rack, and prompt engineering ways of giving it additional instructions on how we want it to behave. Because the way my dentist behaves is different to the way a data analyst behaves. The prompts were behave like a dentist, behave like a data analyst.
And then the second thing is, here’s some other information you probably don’t have that again, a human would ask, if you said to me how many customers have we got? I’m probably gonna say to you, what’s your definition of a customer and where do we hold the data about a customer so I can go look at it and count it for you?
And you want to count today, right? Not last week or next month. And it’s okay to count it to one, So 1,001 customers is okay. Yeah. So there’s a bunch of questions. As a human, you would ask if you’re an expert in your domain. And so this idea of context and reinforcement is passing that back.
So we pass the LLEM prompts to tell it how to behave the data we want it to look at if it doesn’t have access to it already. So we give it access and then the context, additional information we know is valuable to it. So is that what you mean by, The change in what we have to provide versus a SQL statement, which is select this from there, and all we gotta do is give it the code and the data and the machine runs that code on that data and we’re done.
nothing else needs to happen. We don’t need to tell it anything else. Just run this code.
Mayowa: I think the key words you rightly explained it, but I think the keyword there is that because LMS are going to be, or let me say agents let me let, for, let’s just use agents, all right? because agents are gonna be one of the ways we interact with data, when it comes to LLM, agents are gonna be like the main use case, right? So I think the key word is that since agents are not human, there’s a higher chance that in an attempt to provide an accurate response to your queries they speculate. That mean they spend a lot of time, doing some exploratory work, and that in itself have impact on the data system. So because there’s gonna be a lot of redundant queries, things that are not necessary that you will need to fine tune and all of those things. And so because of that I think just, like you said, they have been trained on this massive test that might not even be relevant to what you’re saying.
But then they have to re something back for you. So I think the key word here is that they speculates, and in all of these, it’s an attempt to just give you a response.
Shane: Okay so again if I play it back, if we took a human behavior, it’s like me saying to you, here’s my one terabyte data warehouse. go and tell me how many customers I’ve got. But by the way, there’s no table called customer.
Mayowa: Yeah.
Shane: And now you’ve gotta do a whole lot of exploration, right?
You’ve gotta go and try and figure out what’s a customer called? What table does it live in? How’s it defined? And you’re gonna go and do all this work. And that work takes human time and it takes compute from the system because I’m gonna be writing queries. I think what you are saying is with the L lms, it’s the same, If we say to them, here’s a big blob of data. With no context and no constraints and go answer this question. cause with the reasoning models, and reasoning in quotes,
Going through and building itself a curriculum. It’s building a manifest. It’s saying, I’m gonna go try that.
That didn’t work. I’m gonna go try that. That didn’t work. And it’s trying lots of things. And because it’s a machine, yes, we sometimes see it tell us what we’re doing. But it’s doing a whole of work under the covers. And one of the other things about that is token cost. Because every time it does a task, it’s using a token that costs us money.
If we change the way our data’s platforms are structured, we can make the LMS more efficient, more effective, and require them to do less thinking because we’re giving them hints of what they should use. And when is that the angle you’re taking?
Mayowa: Yeah, correct. The fact that you mentioned the cost thing, make me remember, some of the reasons , so I wrote here you pay for waste. and this is the, one of the reasons why I feel like we need to redesign this is because enterprises, businesses don’t want to pay for waste, Redesigning this system is how we convert, this speculation to speed. Because it’s important for us to know that businesses whether small or large, not in any way we allow waste, So it’s important for us to know that agents. They don’t just query, they probe and they continue to, and there are a lot of redundancy at the end of the day, if we don’t, get this system right, because it is in the nature of agent to probe instead of just getting that.
Yeah. So yeah you’re absolutely correct. Cost is a very important
Shane: And one of the things is at the moment we’re not paying the true cost of those tokens. We pay $20. Okay, now we have to pay 200 a month. Okay, now we’re getting some constraints from Claude and those tools where we can’t just run everything forever before we run out of our, our limit of usage.
But we’re still not paying the true cost. And so while we can do things that are lazy right now and they work and don’t cost us a lot, it’s gonna change, right? And so, you’re gonna start getting the $30,000 bill and we might as well start designing our systems now to be cost effective and efficient.
And I think the other one is speed. If you think about back to your power bi Tableau days, there was a rule of how long you could let a user wait before that report rendered, it was a second or two, and then they start going, this is too slow. And then you think about how much engineering we put in to summarize the data or to give us that performance.
And now you go into an agent, an LLM, and you ask it a question, and then when it’s doing its reasoning models, it’s really interesting to watch how it just sits there and gives you some feedback. It’s working and it’s not dead, but it’s taking way longer to bring back counter customer, which I could have had on a Tableau dashboard in less than a second with what, with, a blog code.
So we’re still experimenting where these agents are best fitting. Okay. So what we’re saying is things have to be changed, Because just throwing an LLEM on top of your current data platform is not gonna be the most cost efficient, not gonna be the fastest it is gonna.
And that waste will hurt us. Okay.
What’s next?
Mayowa: I think we can now talk about what the current data system looks like, right? What I term traditional and like you said, traditional in this case, maybe means several things to several people, right? But for me, traditional just mean the current system where we are able to use languages like structure Korean language, SQL, I, so right now the way we work is we leverage. Platforms, databases, Postgres, name it. All right. And then we just run a query and then we get a result, and that’s what the current system looks like, right? But then when you look at the way agent works I think the right word to use is that agents don’t just use queries. what they do is not just querying. What they do is more like investigating, probing. they want to probe. So we need systems. That are beyond, of course, SQL is very important. Many times people say SQ is gonna be very, we are, we’re always gonna be, I see people learning SQL every day.
I still see a lot of university teaching sq l in their curriculum. So I’m not saying SQL is going anywhere, but I’m saying we need system that will accommodate for other things like natural language. Because these agents will need much more than SQL, like we said, they would need contests.
We need to provide some kind of contest. So there might be, maybe there’s gonna be a need for us to have interfaces that allow for not just the structure query language, but then maybe natural language. So the current data system that we have does not, have that yet. So there might be a need for us to. Incorporate these kind of interfaces, To accommodate for these agents to perform better.
Shane: In the past we’ve always had data catalogs.
So we’ve had this idea of a catalog that set across the technical metadata, the technical context, the technical structure. So I have these tables, I have these columns, I have these values.
And then from a governance and stewardship point of view, we always knew that adding context into that catalog had value.
So that table holds a record for customer. That table holds names, therefore it’s PII that is the table that you query. If you want a single list of customer. These other ones they don’t hold everything or they’ve got duplicates, There’s all this language, this descriptive stuff that was useful.
But what we learned was nobody ever does it. The cost of creating that context was way higher than the value in using it. And yes, we had big organizations where it got mandated and they were certain industries where you had to do it. And yes, we got big tools that automated some of it and that, but in my experience, data catalogs was the tool you bought and two years later you turned off or nobody used it.
I think with LMS and agents, I think that those types of capabilities where we, we bring this natural language context in as text, as description of information is highly valuable. But I’m not convinced that data catalogs of old are the right place to do it. And the reason I say that is I think they’re disconnected.
They’re exhaust they hoover up exhaust. So we hoover up some technical metadata and then we ask somebody. As an extra task to go and add the business context, the operational context of, how many rows are in there, what’s the data quality like and they don’t even have this idea of a gen context, you can’t really, at the moment store prompts or hints for an LLM for an agent, I don’t think they’re fit for, I don’t think they’ll fit for purpose in the original days, but I don’t think they’re fit for purpose now. So I’m with you. I think that there will be a new paradigm coming out about how we hold this language, this description, this context against everything to do with data.
And then that is highly valuable to the agents. And then the way we capture it, to me, it’s gotta be done as close to the creation of the code or the data as possible. So data engineers who are doing the work. Have it in their brain. They know how the accounting customer, I’m gonna create a dim, I’m gonna create a hub and set.
I know the logic because I’ve asked, and I’ve done that work. They’re the ones that we have to make it really easy for them to capture that tribal knowledge into a place that the agent can go and find it. Or maybe we just have probes in our head and then the LLM could ask us. ‘cause when you work in an organization, you probably do it.
You go, oh, I don’t know how we calculated that. And you go and ask Bob. And you know, you, you know somebody in your team that you can go and ask and you get that tribal knowledge outta their head. Maybe, we’ll, I’ve been facetious here, but maybe we’ll have probes in our head where the LMS ask us.
Yeah. So is that what you mean, that idea of that really rich, descriptive stuff? Yeah.
Mayowa: So like I said, it’s summary. I think it’s important for us to take advantage of these agents gonna be a need for us to have a paradigm shift from the normal, SQL against databases. There’s gonna be more things that are involved, like you mentioned, maybe catalog that maybe need to have the data system itself.
Maybe the databases might have something that stores a lot of context in memory, just to provide more context. But I think one thing that is important for this agent is that they need grounding, need to have a lot of information for them to act, anyway, so the current data system, we have to evolve to the point where we have some of these components, integrated into the system for us to take advantage of the agent.
Shane: Let’s just take that comment around probing from the way that you meant it, not me putting a probe in my head for the LL to get my knowledge. And the traditional way we’ve always done it is we’ve taken data from source systems and we’ve bought it into one place and we’ve typically put it in a database of sorts that, like you said, we can write SQL and we can get an answer.
And yes, we played around with no SQL databases and Hadoop and whole of other stuff, but we keep coming back to a database column that stores data in a certain way and allows us to use this standard language to get the data back out. Seems to be a valuable way of working. And then we’ve now got this introduction of MCs where we can effectively.
Create almost an API or a, a network port or an HTDP kind of endpoint for the LMS to talk to a system and get a response, So I need this, give it back to me.
And it’s not writing sql. it might talk to the MCP server and the MCP server might write SQL to talk to the database and get back and then hand it over.
so I look at it and I go, do we know that there’s a bunch of use cases where probing won’t work? And I can come to those in a minute, but why wouldn’t we just fundamentally change the way we work? So rather than grabbing the data from the source systems and put it in one place, why wouldn’t we just expose these MCP services and allow the LLM agents to always just do a one and done query?
Have you looked at it at also actually remove the data warehouse? No. We’ll come to the use cases. Why? That probably won’t work at the moment, but I’m just intrigued by that. It’s, just go away, ask the question, give the answer. If the context is bound around it, if the context is the thing we care about, that’s the pet.
And where the data live really is the cattle. It’s an interesting architecture change to what’s been 40 years of my life.
Mayowa: So I think is an interesting one actually, but of course, we can talk from ante toward the reason why that is not gonna be possible. But I think it doesn’t stop the fact that it make us start looking at things in a different way the way, we used to work.
like you said, I don’t think there’s anything stopping us from doing that. Even from hindsight you start thinking about the cost effect and, a lot of things that might, but I think that there’s absolutely nothing stopping us from exploring that data warehouse today and this is me just digressing. In my experience, the whole idea behind data warehouse, which is consolidating data from different sources and putting it in one place. When you look at it, if we ask ourself this question, has it really, solved the problem? Because I’ve seen places where there are still information that you can’t find in the data warehouse.
That warehouse supposed to be the source of truth, but there are still information that you can’t find in the data warehouse. So if that is still a problem, so what if we have, like you described, if we have a sea of data where we can just throw these CPS to, get information.
I think it’ll be about, but then. there will be a lot of things that goes into making that happen.
Shane: And a high chance of waste. Yeah. A high chance of
Wasted cost , slow. All those things that you talked about at the beginning that actually we need to focus on at the moment. I think whatever we designed would give us those problems.
But that’s at the moment because we’re in the beginning of this whole new wave and so we haven’t really done the rethinking, the re-engineering of what it would look like.
So where’d you get to in terms of, if you started with a blank piece of paper, what would you do right now to build a data platform capability that is LLM, agent friendly.
Mayowa: The first thing is that need a different query interface. Just, like I explained, we need a different query interface and this interface should accommodate for both natural language, And also the structure, query language, SQL and the rest, this interface accommodate for that. But at the same time I think to avoid some of the things that I’ve talked about, like redundancy like waste and all of those things. I think there’s gonna be a need for us to have the data system being able to, determine what query or probe needs to be executed. Just to prevent that waste. Because even when we have this interface that accommodate for several mps that allow agent to run, different queries against the data system, it is important for us to also put, some measures in place to know what query to execute. Because at the end of the day, whatever you get back, it’s not gonna be all useful.
So I’ll say an example, so if you say something like, oh give me the sea strain of the sea strain of maybe battery in the United States. An agent is just probably gonna run a query against different web servers, different webs and just print. Everything is not gonna be useful for you.
But when you take that into an enterprise environment where you need to manage costs, where you need to ensure that you maximize and optimize your queries, that you’ll see that is gonna be a big problem. So for me, I think the first thing I will look at is that we need a different query interface.
That we need to find a way that the data system, determines what query to execute. So for example, the database know, if there’s a way to, of course there’s gonna be a need to implement maybe metadata storage and all of those things to give an idea of what currently exists within the data system. So that determines immediately this is what is available. So if you run a query that is not relevant to what is in the device, you just don’t execute it. So that is the way it is in my head right now. So we need a new interface. We need something within the data system to determine what query need to be executed. is the way I will start designing.
Shane: What’s interesting is this idea that when we move from humans to machine, we get infinite scale. So that example you used of, what is the sales trend of batteries in the US
A human, I have some natural constraints. I have natural constraints of time. I can’t spend two years going and finding that number.
I have a natural constraint of knowledge, right? I’m gonna Google it. I’m gonna find some websites, and then I’m probably gonna even run outta time or get bored, and I’m gonna stop. Whereas when we talk about , the agents, it’ll scale. If you let it right it’ll search every website in the world.
If you let it, if you till it to, it can run a thousand human, I don’t know. What is it? CPUs for the computer, miles per hour for a car? What’s a agent cycle for? For number of human hours. So it, it can run a lot of human hours in a short amount of time for a cost.
Anything we do that is a Pattern based on a human constraint of I don’t have time, I can’t scale myself, that disappears. And we’ve gotta be really cognizant of that, or we’re gonna get massive waste again, like you say, I think the other thing is this idea of, if you look at human behavior, if you’re in a data team and you’re in a team of five to nine, you’re gonna find that normally you’ll have a data modeling expert, you’ll have a data collection, source system expert, you’ll have a data engineering expert, you have this experts and you are naturally gonna go and ask the expert for some help. Hey, I am looking at this and I need to model it. And I know we, we are a data vault is our standard. So can you just. Gimme help because I’ve never done it. I don’t do it very often. Or can you peer review And one of the things we’ve found as we’re building this out is that when we had a single agent, so our agent’s called 80 when she was the only agent we used to flutter. So we would say, go and do this work. And she’s just time slicing her skills all over the place. And we always got back an okay response as soon as we then broke her out into other agents.
So we have 80 80, the data modeler, 80, the engineer who goes and figures out the transformation rules and then 80 debos. And so we talked to Ada Deboss and she knows about these other versions of herself. Then she goes, oh, okay, the next thing I need to do is model that data. And she talks to a, the data modeler.
And what that means is we provide a, the data modeler, a bounded context. We give her very specific prompts around You are a data modeler. You’re not an engineer, you’re not the boss, you’re not the bi you, this is your job. These are your skills. We give her a bounded subset of context. you can look at the data structures but you can’t go and do data quality tests.
Because we’re talking about, in this case, conceptual modeling. That’s not your job. Another 80 will then take what you’ve done and make it better or do her task. And what we find is that specialization of skills and then that handoff, which happens in a team, but you don’t really see it, if you then programmatically do that with the agents, we seem to get better responses.
So I’m with you. I think this idea of. What interface, what language, what set of skills, what persona can be bounded and then handed off all over the place. And that’s, I think, where we’re gonna need to, I still think sql to query data if we need to do that
is gonna be done.
However, we’ve had great success giving images to the lms, not data,
but it’s expensive. It’s wasteful. So if I give it a photo of a an image screen capture of an Excel spreadsheet,
It’s gonna do really well with it. But it cost me a lot more tokens than if I give it the CSP.
So I think it’s, again, that trade off between outta the possible right now and then the cost and waste of doing cool stuff.
Mayowa: So I think part of the reason why I also mentioned that it’s, important for us to have this interface that accommodate for both natural language and also SQL is, right now, part of the way I work is I actually have bunch of queries that I’ve written in the past.
And I just dumped them in my LLM dump a lot of them. And right now I just ask questions. And because this LM already have history of my queries that I’ve used, TPV, how to calculate TPV, how to calculate TPC and all of those things. So I just say, Hey, can you give me, develop a query to, and it does that and then gimme the output.
So I think part of, what you’re saying is, providing contest is. There’s still gonna be a lot of work to be done around, contest, so giving queries that we’ve used in the past, or maybe anything that can provide more grounding. We actually, help resolve some of these issues.
I’ve seen it work firsthand. It’s working perfectly for me. There are a lot of requests that I don’t spend my time developing the query anymore. My, LLM just, does that for me,
Shane: And that’s a really good point, is this multimodal thing. Joe Reese talks about multimodal arts. And so this idea that no organization actually uses one data modeling technique for their warehouse, They may say they’re dimensional star schemas, but there’s some relational stuff in there.
There’s some sorts. Yeah. We always have more than one modeling technique, and I think we’re gonna end up with more than one language. And that multimodal language is gonna be important. And so I, I’ll give you an example we. Presented all our documentation to 80 for our product.
And so we describe what we call change rules, which are transformation code. And we have a set of language you have to use for it. And so we described, how the rules work, what the structure is, what the structure of the language is, and there’s some examples,
if you want to go and pivot, do this if you wanna un-pivot, right? But it was all in text. And so when you know, somebody comes in to our platform and they go, I need to transform this data and they just write in plain text, I need to transfer this data, how would I do it? She came back with an okay answer.
But it was just, okay. And sometimes it was just wrong, she would hallucinate and we’re like, yeah, that’s not how our product works. And then what we found was effectively we run a multi-tenancy architecture. So we stood up another tenancy, or one we already had for our partners called Alliance, and we pushed example transformation code, our example, change rules across every customer we had.
We took the rule itself, not their data, and we said, this is a rule we’ve applied before. So your, exact same example of yours, of here’s a blob of code, this is a rule that we’ve used before. And we then created an MCP server that 80 could see, to see those rules.
That’s when we broke off to 80 the change rule.
And so all she does is if you ask her how you can transform this data in natural language, she will go and search those rules. But she’s effectively searching a code repository that is highly opinionated and highly structured, the language is the same. What’s in the language is different. And our the response back we get is so much better now.
And so the thing we found though was while we had the rule, the logic the language of the rule, we had no context. We never wrote down
Why we were doing. So as soon as we added that, a natural language of this rule is to take stats New Zealand data, which is being summarized as columns and unpivot it to rows so that we can use it later when we need a row per record.
Then she’s ah, now she’s getting both the, the thing. the same as you are saying is that if you take your blobs of code that you use on a regular basis, and I think you, when you talk about TPV and TPC, you are saying there’s some metrics in there, if you then in that code, put in the definition of the metric, TBV equals and then a bunch of texts, and that’s as a comment in that code, then the LMS are gonna get both a structured piece of code and context.
They’re gonna get sequel and they’re gonna get natural language. And I think that’s where we’ll end up.
Mayowa: going back to your question, if you ask me what are the things I need to, think about if I’m going to design what this system should be, I think the interface is gonna be very important. And also, how to manage what query needs to be executed to avoid waste, redundancy. And, I think that is the way I’m gonna think about it.
Shane: So let’s take that example where you’ve got you and blobs of code that you have found highly valuable and you’ve already tested putting that code as a reinforcement model, given that context of the code to an LLE and been able to ask questions and get back the help that you needed.
And let’s say that you do extend it out where you actually define what those metrics are in, in natural language, so it has a richer context. And then you’ve got three other people in your team. Who need to do the same thing, like right now, what would you do? Where would you store it?
Where would you surface it? what interface would you use to create it, to share it? Like how would that work for you right now?
Mayowa: Now the way it works, this is just for my personal use. I’ve not had any reason to share with anybody. But I think that also, point to what I was talking about when it comes to, conceptualizing what this data system should look like, I think there’s gonna be a need for us to have part of the data system, maybe the database, a part of it that stores these I don’t know whether it’s gonna be a meta store, or whatever, that stores this information. And the reason being that regardless of who is running this query or who is submitting a probe, they have access to the same information.
And that information can help provide more grounding the LLM or the agent, or MCPO, whichever one that you’re thinking. I think that part of what we need to think about is a part of the data system. Maybe this can be the database. Now maybe this open a new opportunity for, database research to see how we can, if part of we can store, information that provides more grounding to JLLM.
So that is the way I’m gonna think about it, but right now I’ve not had any reason to actually explore.
Shane: it’s an interesting one because if we think about the fact that we’ve always stored our operational data, O-O-O-T-P data separately from our analytical data,
Our OAP data, that’s because in the past we never really had a technology that allowed both to be stored efficiently in the same place and queried, they were two different query pads, two different storage patterns, and that’s not true anymore. We’ve got tools out there like single store that say I don’t work with ‘em, so I dunno if it’s true, but they say they do that, yet nobody’s really adopting it, that I can see, we still keep it separate.
And so when we start bringing this idea of a context store Victor databases, we seem to be the thing, but actually a lot of the times you don’t have to use those. You can use anything. So I’m intrigued like you, to see whether we end up with yet another database,
We now end up with.
Databases that store the data and the context side by side. It is an intriguing place to be. And then do we end up with a thing that I call the context plane, which is the idea of a shared centralized layer of context? Or do we end up with a context grid? The idea that context is stored next to the data and then something else federates it, provides a grid type architecture. And so again, we’re at the early days where lots of people were exploring and saying what works and what doesn’t. So just on that, just to close it out, so this is something you’ve been thinking about in your spare time, right? You’re not part of a software company building this, your organization.
You’re not part of a team building it out for them. This is something that just natural, inquisitive, nature going, yeah, that’s cool.
Mayowa: Yeah. Pure, natural, inquisitive. I’ve read a lot of papers. There’s this interesting journal that came out of Berkeley. I can’t remember what the title is now, but it’s very interesting. They did a very fantastic job around this conversation too.
So yeah, for me, I’m not part of any team actively developing something in that space, but it is just something that I’m just interested in.
Shane: And the next step is you’re gonna start writing. You’re gonna start writing your thoughts, starting write your explorations.
Mayowa: That’s part of what I’m doing. By the time you release this I want to listen to this conversation again because some of the things that you said, I think that are really interesting. I want to look into them more deeply. So yeah, I’m just documenting my thoughts right now.
Shane: And my advice to people is document lightly and document early. So share lightly, share early. don’t wait for this podcast to come out, document what you think right now and then write it up, share it, and then think about it a bit more and then write it up and share it. because people often find the journey of the way you think, as interesting as the answer. And what I say is by writing, it’s forcing you to think with clarity. you think, you know something, you’re like, oh yeah, I think I know how that’s gonna work. And then you write it down and you’re like, yeah, no that’s bollocks, that’s not gonna work.
So that art of writing just makes you think, ‘ writing is structured it has beginning, middle, and end. it’s gonna force you to story, tell to yourself and validate what you think is gonna happen as, so yeah, my recommendation to everybody is, write small bits.
Push it out early, it helps you think it’ll change. And that’s okay. it’s not a book, It’s not something that you can’t change. It’s Hey, I thought this and now I think this, and I think that’s better than what I thought before. But I had to jump from A to B2C to D to get to E.
Alright when this does come out, how do people find what you are writing? Have you worked out where you’re gonna publish it?
Mayowa: If I’m gonna post, it’s gonna be on my LinkedIn if I’m gonna leverage any other platform. I also put it on my LinkedIn. So the time I’m done with this, I think everybody can find it on my LinkedIn.
Shane: Most of us are now writing on Substack ‘cause LinkedIn sucks for long form content. So I’ll encourage you to create a Substack yeah. And then till everybody on LinkedIn, that’s where the long form content is. ‘cause LinkedIn’s kind of killed the ability, which is really sad. ‘cause actually I’d rather just write in one place.
Excellent. People can see how you’re exploring and what you’re learning and what you’re sharing. I look forward to it.
Mayowa: Yeah. Thank you.
Shane: I hope everybody has a simply magical day.
«oo»
Stakeholder - “Thats not what I wanted!”
Data Team - “But thats what you asked for!”
Struggling to gather data requirements and constantly hearing the conversation above?

Want to learn how to capture data and information requirements in a repeatable way so stakeholders love them and data teams can build from them, by using the Information Product Canvas.
Have I got the book for you!
Start your journey to a new Agile Data Way of Working.