


Trust Rules - Automated Data Validation, AgileData Engineering Pattern #3
The Trust Rules pattern provides automated data validation to ensure all incoming data is fit for purpose and trustworthy
Trust Rules - Automated Data Validation
Quicklinks
Agile Data Engineering Pattern
An AgileData Engineering Pattern is a repeatable, proven approach for solving a common data engineering challenge in a simple, consistent, and scalable way, designed to reduce rework, speed up delivery, and embed quality by default.
Pattern Description
The Trust Rules pattern provides automated data validation to ensure all incoming data is fit for purpose and trustworthy.
It bakes in essential checks such as unique business keys and business effective dates, which run automatically upon data load or table refresh.
Users can also define custom validation rules for specific columns.
Results are collected, persisted, and surfaced via applications or alerts, with the system optimising validation for cost and speed through smart partitioning and clustered columns.
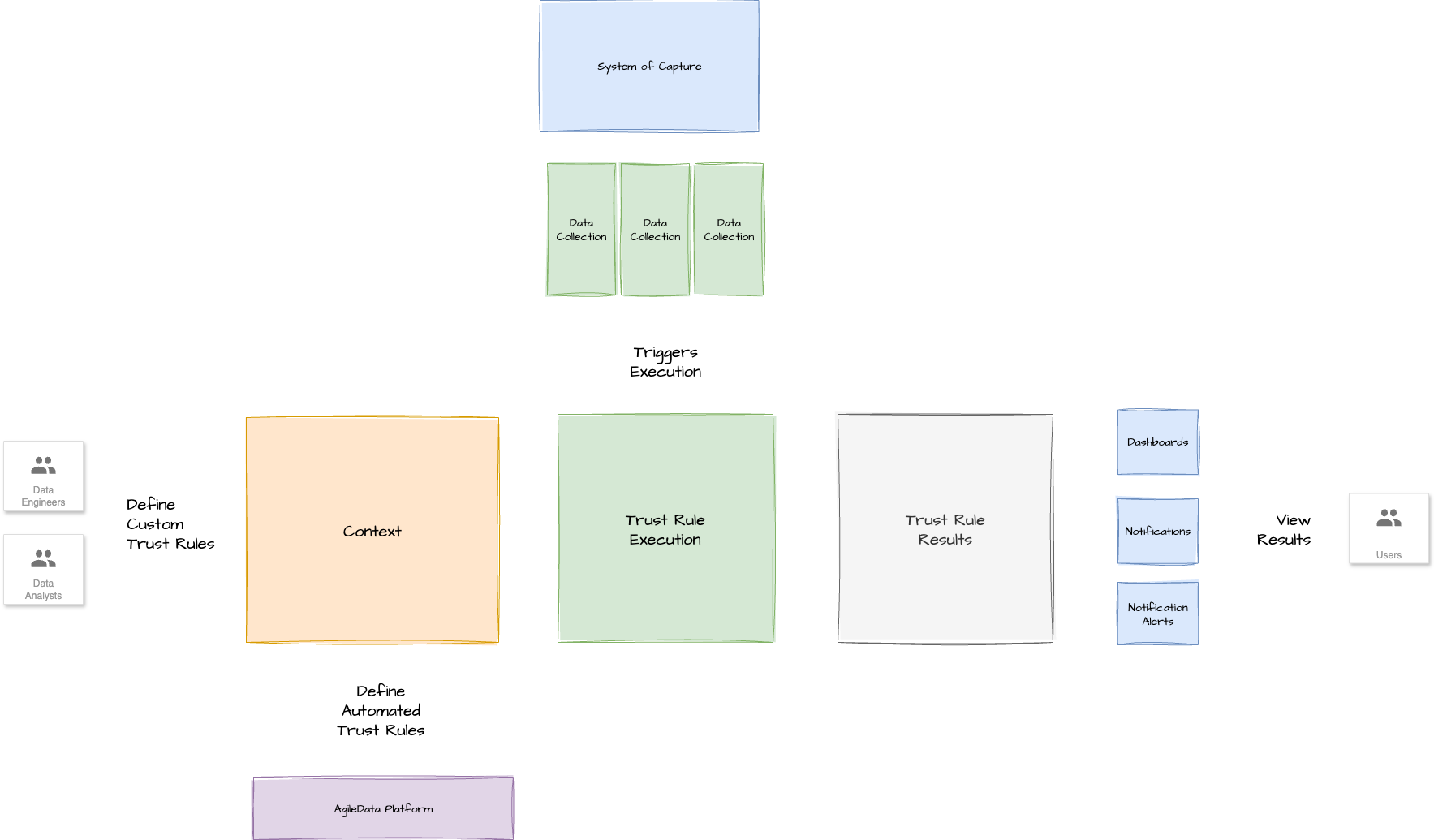
Pattern Context Diagram
Pattern Template
Pattern Name
Trust Rules - Automated Data Validation
The Problem It Solves
You know that moment when you're working with data, and you're just not sure if you can actually rely on it? Is it accurate? Is it complete? Are there duplicate entries mucking things up downstream? Trust Rules effectively solve the problem of ensuring data is "fit for purpose" and addressing the "bane of engineers lives" when it comes to data validation. When teams don't automatically validate data, crucial issues like duplicate business keys or missing effective dates can go unnoticed, leading to untrustworthy data and downstream problems. This pattern ensures that a core set of necessary data quality checks are performed automatically, removing the burden from individual engineers to constantly remember and implement them
When to Use It
Use Trust Rules as a default, not an exception, and have them "baked into the product from day one"
Use this pattern when:
When new data arrives or a table is refreshed.
When you need to "check its fit for purpose" and ensure data is trustworthy.
To ensure fundamental data integrity, such as checking for unique business keys or the presence of a business effective date for every row.
When specific, user-defined validations are needed for particular columns (e.g., email validity, phone number format).
To reduce the effort and cognitive load on data engineers by automating common, mandatory checks.
It's especially helpful for establishing a baseline of data quality that is always applied, regardless of context
How It Works
This pattern establishes a robust, automated data validation system.
Trigger:
The pattern is initiated when:
A task is identified that requires data validation, typically when new data is loaded, turns up, or a table is refreshed.
This process is often initiated by a PubSub message indicating that a table refresh is complete
Inputs:
Pre-defined automated trust rules (e.g., unique keys, effective dates).
Pre-defined user applied trust rules (e.g., not null, is number, is email, is date).
User-specified trust rules (e.g., email domain validation, value between, regex, masking, formulas).
Steps:
A table is loaded or refreshed with new data.
Upon completion (triggered by PubSub), a series of data validation checks are run against the new data.
Automated (baked-in) checks are executed: These are mandatory, cannot be turned off, and include fundamental validations like checking for unique business keys, a business effective date for every row, and non-nulls in strategic places.
User-specified checks are executed: Users can define additional, custom validation rules for specific columns they care about (e.g., validating email formats or phone numbers using regex). The logic for these rules can often be leveraged from open-source libraries.
The results of all checks are collected and persisted into a data layer, treated like any other data.
These results are then surfaced to users through various channels such as an application interface, reports, or alerts (e.g., via Slack), with the severity of the failure dictating the notification method.
A history of all validation rules run against each table (down to a column level), including successes and failures, is maintained
Outputs:
Validated data that is confirmed as "fit for purpose".
A clear, traceable history of data quality for every table and column.
Early identification of data quality issues, allowing for immediate action and reducing downstream problems.
Increased trust in the data for all users and stakeholders
Why It Works
This pattern works by automating the foundational data quality checks that data engineers would otherwise have to manually implement for every new dataset. It removes the burden of remembering and applying these core rules, allowing the "machine to do it for me". By baking these rules in "by default and not as an exception after the fact," it ensures consistent quality from day one. The system tells the user if they've done "something dumb," providing immediate feedback and fostering correct behaviour without constant manual oversight.
Furthermore, the pattern works by optimising the validation process for cost and speed. By moving from external, expensive, or less controllable tools to an internally managed system, and by leveraging database features like partition pruning and clustered columns, checks can be performed more efficiently and cheaply. For instance, with a column-oriented storage engine like BigQuery, only the relevant column for a specific time window is scanned, significantly reducing compute and query costs. It turns code into a shared asset, not a fragile mess of files (this is for Git, but the underlying principle of making data a shared, trustworthy asset applies).
Real-World Example
Imagine a data engineer onboarding a new "history tile" of data. With Trust Rules, they don't have to manually write checks for every fundamental requirement. The system automatically performs checks to ensure there's a unique business key for every row and that the effective dates are correct, without the engineer having to worry about these basic validations.
Separately, if a user specifically cares about an "email" column within that data, they can define a user-specified trust rule to ensure that "all the values loaded into here are from a specific email domain" This check runs automatically when new data is loaded, and if any emails are invalid, the system persists the result and can send an alert, perhaps to Slack, notifying the team of the data quality issue.
Anti-Patterns or Gotchas
"Data quality on everything everywhere, every time": Applying every possible data quality test to the entire table, regardless of necessity, leads to excessive cost and performance issues. Some data becomes immutable, meaning earlier checks don't need re-running over the full historical dataset. Smart partitioning and focused checks on the latest data window are crucial.
The "Noise Problem": Creating too many trust rules, especially for columns or conditions that don't genuinely impact data trustworthiness or stakeholder value. This can lead to a deluge of alerts that are ignored, causing truly important issues to be missed. If "nobody cared about that rule," then it shouldn't generate noise.
Using external, expensive, or overly technical data quality products: While good for initial exploration, relying on external services that are difficult to maintain, run, or lack granular control (e.g., over partition pruning) can become a "technical" and "expensive" anti-pattern. Bringing the pattern "back into the core of our context plane and our execution patterns" allowed for greater control and cost-efficiency
Tips for Adoption
Bake it in by default: Ensure that fundamental, non-negotiable data quality checks (like unique keys, non-nulls in critical fields) are automated and unchangeable from the outset.
Provide user-defined flexibility: Allow users to easily specify additional validation rules for data columns they specifically care about, empowering them to ensure quality for their particular use cases.
Persist and surface results: Store the results of every rule execution as data and make it easily accessible through reports, applications, or alerts, adjusting the notification method based on the severity of the failure.
Optimize for cost and speed: Design the system to leverage underlying database capabilities (like partitioning and clustering) to scan only necessary data windows, reducing query costs and execution time.
Prioritise value over quantity: Only apply trust rules where they truly add value and address a genuine concern about data trustworthiness, rather than implementing "data quality on everything everywhere, every time". This helps reduce noise and ensures that teams focus on critical issues.
Related Patterns
PubSub: Used as the mechanism to trigger trust rule execution after a table refresh is complete.
Load Patterns: Trust rule results data can be used to assess if data is arriving at the expected time, indicating missing expectation levels from the organisation.
Context Plane and Execution Patterns: The trust rules themselves are defined within a "context plane" and are part of the broader "execution patterns".
Data / Reporting Layer: The results of trust rule executions are persisted in a data layer and surfaced through a reporting layer
Press Release Template
Capability Name
Trust Rules
Headline
New Trust Rules Feature Ensures Data is Always Reliable and Ready for Use for Data Engineers and Information Consumers
Introduction
We're thrilled to announce the launch of Trust Rules, a powerful new capability designed to automatically validate your data. This feature provides immediate confidence in data quality for data engineers and business users alike, ensuring all data is "fit for purpose" and trustworthy from the moment it lands. It's about ensuring data is reliable by default, not by exception signed for anyone who needs to effortlessly stack data from multiple similar tables, such as those from multiple publishers in a data clean room, without having to write intricate or "horrible SQL". It delivers a "magical" experience by making data integration both easy and efficient
Problem
"As a data engineer, I used to have to constantly remember to build standard data validation checks for every new dataset, like making sure keys were unique or that effective dates were always present. It was a real pain, and if I missed something, it could cause big problems all the way downstream. The 'noise problem' from too many irrelevant alerts also made it hard to spot what truly mattered."
Solution
Trust Rules automates the foundational data validation process, making it easy and largely automated.
Whenever new data is loaded or a table is refreshed, the system automatically performs essential, baked-in checks, such as verifying unique business keys and the presence of a business effective date for every row.
Furthermore, users can easily define their own custom rules for specific columns, like ensuring all emails are valid or checking phone number formats, without needing to write complex code.
The results of these checks are collected, persisted, and then clearly surfaced through an application, reports, or alerts (e.g., via Slack), with the severity of the failure determining the notification method.
This not only ensures data integrity but also optimises the validation process for cost and speed by leveraging smart partitioning and clustered columns
Data Platform Product Manager
"With Trust Rules, we're taking away the 'bane of engineers' lives' by automating core data validation, making our data platform significantly more auditable and profoundly boosting trust in the data. This foundational capability means our teams can focus on delivering high-value work, knowing the data quality is inherently managed and consistently applied."
Data Platform User
"What I love about Trust Rules is that I don't have to constantly worry if the data is accurate; the system automatically tells me if I've done something 'dumb' before it becomes a problem. Now, when I load data, I just know the essential checks are handled, and I can easily add my own custom validations for what I care about—it's truly a game-changer for my confidence in the data”
Get Started
Trust Rules are baked into the platform by default for all core data, running automatically when new data arrives or a table is refreshed. To leverage user-defined trust rules for your specific data quality needs or to learn more about the automated validations, please consult the AgileData platform documentation or speak with your Data Platform Product Manager.
AgileData App / Platform Example
Notifications Dashboard

Trust Rule results for a Tile

Apply Predefined Trust Rule

Create Custom Trust Rule

AgileData Podcast Episode
AgileData Podcast Mind Map
AgileData Podcast Episode Transcript
Shane: Welcome to the Agile Data Podcast. I'm Shane Gibson. And I'm Nigel Vining. Hey, Nigel, another episode of Agile Data Engineering Patterns. Today we are going to talk about trust rules at a high level this time because this one has patterns within patterns within patterns. So let's start from the beginning.
Nigel: Cool. So trust rules, one of those bane of engineers lives, but it was something that we believed and passionately we believed it should be easy, largely automated and baked into the product from day one. Trust rules was something that we did by default and not as an exception after the fact. Trust rules effectively.
They're data validation rules, as I talked about on our previous bytes. Um, when a table is loaded, when new data turns up, we refresh a table. Then as I said, we use pub sub to say, Hey, I'm done. What do you want me to do now? So one of those things that we do off the end of a table refresh because new data's turned up, is basically to turn around and say, cool, new data's gone to the table.
We need to run data validation on that data. To check its fit for purpose. So what we then do is we turn around and we basically run a series of checks. Largely they're automated things like, are the business keys unique? Do we have a business effective date for every row? Those run every time, regardless.
You can't turn them off. You can't change them. They are baked in. 'cause if we have duplicate rows, then we've got a problem all the way downstream. The second level of checks are user specified. Ones a user may say. Hey, I really care about this email column. I need to make sure all the values loaded into here are valid emails.
So the user will effectively say, Hey, run an email validation check when this table is loaded. Once we've run those checks, we basically grab the results. We persist them. Uh. Reporting report to notify users if any of them fail and how many of them fail and we keep track of them so we can see the history for every table down to a column level, what validation rules have been run against it, and all the successes and passes.
That's in a nutshell.
Shane: So effectively we define the the trust rules which sit in our context claim. We then execute them when they need to be executed. We store the results of every execution as if it's data, and then we surface that data, those results, we call them in any way we want to. Maybe in the app, maybe a report, maybe an alert coming out via Slack, depending on the severity of that failure.
It's interesting, the name trust rules, you often hear of them called data quality, data validation. Why did we call it trust? Actually, these are the things that help people trust the data they're seeing. So that's what we wanna do. We wanna make sure it's trustworthy. And that's why we picked trust rules as a name.
And then the other thing is if you're a data engineer, there's a bunch of automated tests you always have to build, like you said, are the keys unique? Do we have duplicate values? All those kind of things. And as part of the trust rules patent, we just automated them as the user of the system. I don't have to care.
If I do something dumb, the system tells me I've done something dumb and it stops me. I don't actually have to keep remembering that there's a core set of things that I need to do because the machine does it for me, and I think that's part of it, is that I don't need to do the effort. I don't need to remember to do it.
It just. Gives me a, a lovely message when I'm doing the wrong thing and I change what I do. So I think that was actually one of the biggest wins for us when we implemented this patent.
Nigel: Yeah, exactly. The built in rules, by default, it's fantastic because we can onboard new data, you can chuck it in, you can tick a few boxes and get that pipeline basically productionized.
Within an hour or two. And then you don't have to worry about, you don't have to go, oh, I need to make sure that's unique. Oh, I need to make sure that's not now. Or I need to make sure that's a proper sequence. Because effectively we say, Shane has just onboarded a history tile. These are the things that a history tile has to have checked to be safe.
And we do those checks, and it doesn't actually matter what data's going into that tile because we still need to make sure we've got a. Unique business key for those rows. We need to make sure that the effect of those rows is correct and we're checking for nails in some strategic places. So all of those things, there is no context, none have to worry about.
It's not afterthought, it does it automatically. So you just load your data. Use it, the checks being taken care of for you.
Shane: And then there's some things I do care about. So then I use the user to find trust rules and I can create, is it an email address? Is it a phone number? All those re rejects field to make sure it's got one.
I need all those kind of, not custom, but those commonly applied ones. But I don't want them applied every time. And one of the keys that we found was. That the logic for those user defined trust rules, effectively the rejects or the masking or the formula to say is this thing, this thing. It is readily available out there.
There's a large number of open source products where basically you can grab that library of data quality rules, and you can apply it yourself. You don't actually have to reinvent the wheel for that one, but from memory, in the beginning, we did actually use a Google Cloud service. To define and act, build and execute all the data quality checks.
And then a while ago, I think it was a year or two ago, we actually bought it back into the core of our context plane and our execution patterns. Why was that?
Nigel: Yeah, that's right. We started out using an open source product that Google wrapped. It was basically a data quality. Engine defined by the YAML files, which described all the tests, which were basically the sequel that would be run, and that was pointed at tables and it executed those tests and it produced the results and stuff.
And that sort of got us up and running and gave us a flavor of how these things work. But it became apparent that it was quite technical to maintain it. And run it. And we wanted to pull basically trust rules back into the app and make it as simple as ticking a box rather than have to configure the separate product outside.
The second thing was it was quite expensive, relatively a little bit more expensive. With the way the validations were run. We had a little bit less control over. Partition pruning and using clustered columns. So effectively we took the Pattern, the open source Pattern, and we basically wrote our own version of it.
We followed some of it, we wrote our own, and effectively we sped up the tests. We can do a lot more tests and less time 'cause there was less building on the fly happening. And they were tended to be cheaper because we were doing a lot. Smarter petitioning pruning because we knew the watermark of the data we just loaded so we effectively could pass.
Hey, we've just loaded 14 days worth of data. You don't need to check prior to that 14 days 'cause we've already done that. So we did a whole lot of smart stuff to just speed up those tests and make them cheaper. And that's effectively what we've had now for, oh, it's probably coming up two years. It's quite a while.
Shane: I think that's probably the core anti-patent that we see, isn't it, is a data quality on everything everywhere, every time. So that idea that you have to scan the full table for every data quality test is an anti-patent because there are certain tests where the data becomes immutable. That test will never change.
So you can run it, store it. And then there are other tests where, for example, you want to check how many distinct values there are in a particular column. Then you are going to have to table scan or do something smart and to reduce the cost of running that.
Nigel: Yeah, and that's what I mean by we know those because we have architected the tables themselves.
We know which tables are partitioned and those are the ones we will partition scan for the data. We know which ones are clustered, so they're the ones typically where we're gonna look at. Every key, like a concept table of customer IDs, because we would automatically cluster the customer ID to do a is unique check on that clustered column is basically a freebie because under the covers, the database knows that column is unique.
We don't have to do a lot of work to do that. So on a concept, we only care that the key is.
We are scanning a window of data in multiple partitions because we're looking at actual attributes, like you said, email addresses, but we don't need to look at the email addresses from last month because we've already checked those. We only need to look at the email addresses that have turned up today, yesterday in the current window, and we can do that very cheaply.
'cause basically we are saying just grab the email address column for. Two days, three days, and check them. And it's a tiny shard of data and it works really
Shane: well. I think that's one of the benefits of using a column or storage engine engine under the covers like BigQuery because we just grab one column outta the entire table and records for a small period of time.
And therefore the compute cost, the query cost is, is tiny. And the other one is when you do the everything everywhere, every time is the noise problem. And when I first started off, because it was so easy for me to create trust rules, I would add them everywhere and never look at them, and then I'd start getting massive amount of alerts because actually a column I really didn't care about that much, or we didn't need to validate for any trust reasons, would just keep giving me constant problems.
It wasn't that the data was untrustworthy, it was that the data didn't quite match that rule, but nobody cared about that rule. Nobody was gonna go fix it in the source system. And so that noise to signal ratio is always a problem. And we can go through lots of examples in more detail around how we do trust rules, but.
One of the trust rules we'll talk about in the future is the idea of the load patterns. So using the load patterns for tables to determine when we may be missing the expectation level from the organization of when data should turn up. So again, you can use this trust rule results data to solve many problems, but the key is I only put it on where it has value.
Otherwise, you spend money where you don't need to. And you've gotta go manage thousands of messages and you're just gonna ignore them and miss the ones you really care about.
Nigel: Exactly. Yep. Keep it simple.
Shane: Yeah. Reduce that complexity. All right. That's another agile data engineering Pattern in the can. I hope everybody has a simply magical day.