
Data Engineering Patterns for the AgileData Event Tile, AgileData Engineering Pattern #5
The Event Tile Data Modeling pattern captures business processes and transactions within AgileData's three-layered data architecture, modeling "who does what" at a specific point in time.
Automated Load Patterns based on Source Data Profiles
Quicklinks
Agile Data Engineering Pattern
An AgileData Engineering Pattern is a repeatable, proven approach for solving a common data engineering challenge in a simple, consistent, and scalable way, designed to reduce rework, speed up delivery, and embed quality by default.
Pattern Description
The Event Tile Data Modeling pattern captures business processes and transactions within AgileData's three-layered data architecture, modeling "who does what" at a specific point in time.
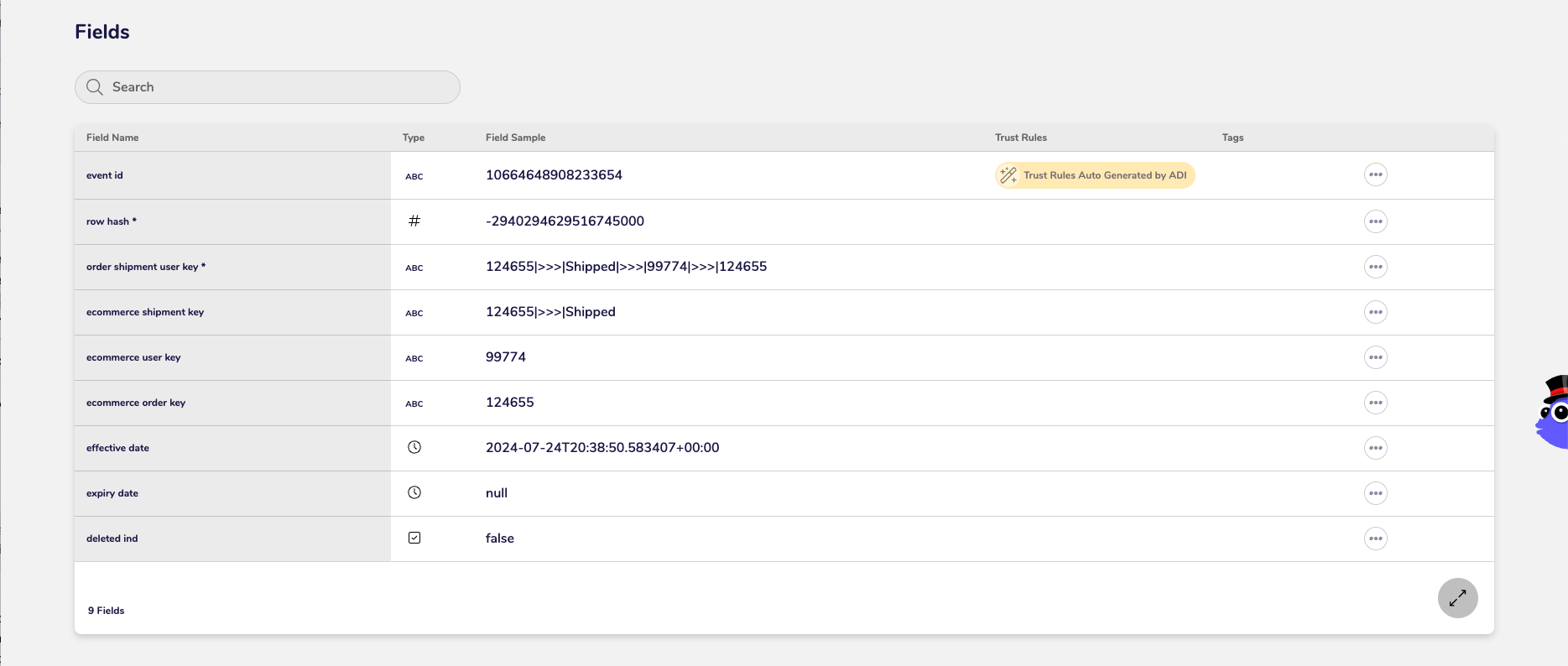
It achieves this by storing only a small number of core business keys in insert-only event tables.
These event records are then automatically hydrated into a "consume tile" by joining with all relevant detail attributes that were current at the exact moment the event occurred, ensuring an accurate, time-staged narrative.
This provides data consumers with a rich, wide, and historically accurate view of events, simplifying the querying of complex historical changes and state transitions.
Pattern Context Diagram
Pattern Template
Pattern Name
AgileData Event Tile
The Problem It Solves
You know that moment when you're dealing with complex business processes, like an order progressing through various statuses (entered, updated, approved, paid), and you need to understand exactly what happened at each point in time?
Or when a customer's details change, and you need to see the state of an event at the exact moment it occurred?
If you only use simple Concepts and Details (C&D) for modelling, tracking these complex, temporal changes becomes a real headache, making it hard to query and maintain a consistent view of historical events.
The Event Tile pattern solves this by providing a clear, point-in-time view of business processes, ensuring accurate historical context for every transaction
When to Use It
Use this pattern when:
You need to model a business process or transaction that happens, such as a customer ordering a product or an invoice status changing.
There are complex changes within the event itself, or if the attributes related to the event's participants (like customer addresses) change over time, and you need to capture the state at the moment of the event.
You require auditability and accountability of changes, providing a clear history of what happened, when, and why.
Transparency of progress and impediments for data changes is valuable, similar to how transparency aids team coordination.
You're working within a three-layered data architecture consisting of history, designed, and consume layers, and the event represents a core object type in the designed layer.
You need a single, consistent pattern for loading various types of event data, regardless of their native source format
How It Works
This pattern works by creating lean, insert-only records that represent a specific business occurrence, then richly hydrating them for consumption.
Trigger:
A business process or transaction occurs, or a significant change happens to a designated "driving concept" within that process. For example, a new order is placed, or an existing order's quantity or status changes.
Inputs:
A set of business keys that uniquely identify the event and its associated participants at a specific point in time (e.g., customer ID, order ID, product ID).
A driving concept identified for each event tile to dictate when new event records are inserted.
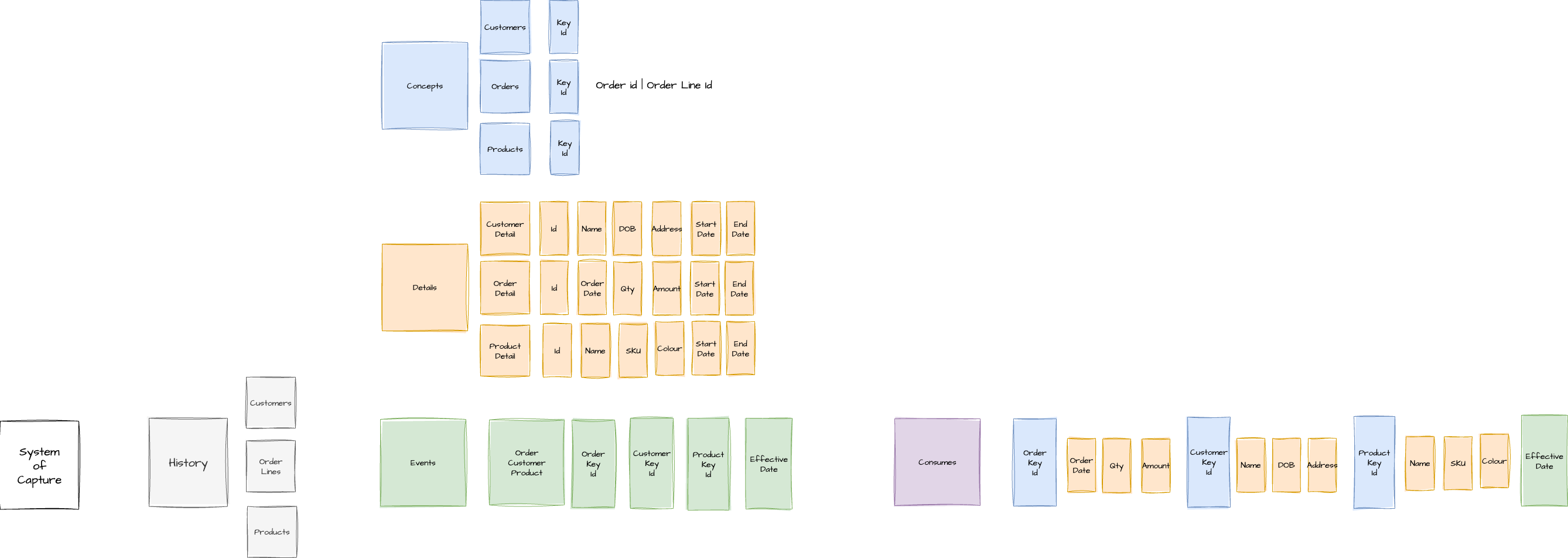
Concepts: These are the "things" involved in the event, such as Customers, Orders, or Products, which hold unique identifiers.
Details: These are the attributes related to the Concepts (e.g., customer name, product description, order quantity).
Steps:
A business process or transaction is identified for modelling.
An Event Tile is created, designed as a simple table that is a collection of only business keys. These tables typically contain no more than seven or eight keys, often closer to three to five, representing a "who does what" structure (e.g., customer orders product).
Event tables are insert-only; new records are only added if the unique situation described by the keys and effective date has not previously occurred.
Each event record includes an effective date (or business effective date), capturing the precise moment the event happened.
A driving concept (e.g., the 'order' in a 'customer orders product' event) is chosen. Any change to this driving concept (like an order update or quantity change) triggers the insertion of a new event record.
Records in the event tile are never end-dated. Instead, windowing functions are used during query time to determine which event was active at a specific point in time and what details relate to it.
The event tile is then automatically hydrated into a Consume Tile. This involves joining the event's keys to the relevant Concepts and their Details, ensuring that the attributes picked up are those that were current at the event's effective date.
For native source events (like Google Analytics data that arrives as an event), they can be unbundled into their component parts (concepts and details) and then re-hydrated back into an Event Tile. This standardises the loading pattern. Alternatively, if unique elements within the native event (e.g., page titles from GA4) need to be reported on, it can be more efficient to treat that native event as a Concept directly and split out the relevant data
Outputs:
lean, history-preserving Event Tile table consisting solely of business keys and an effective date, representing a specific business occurrence.
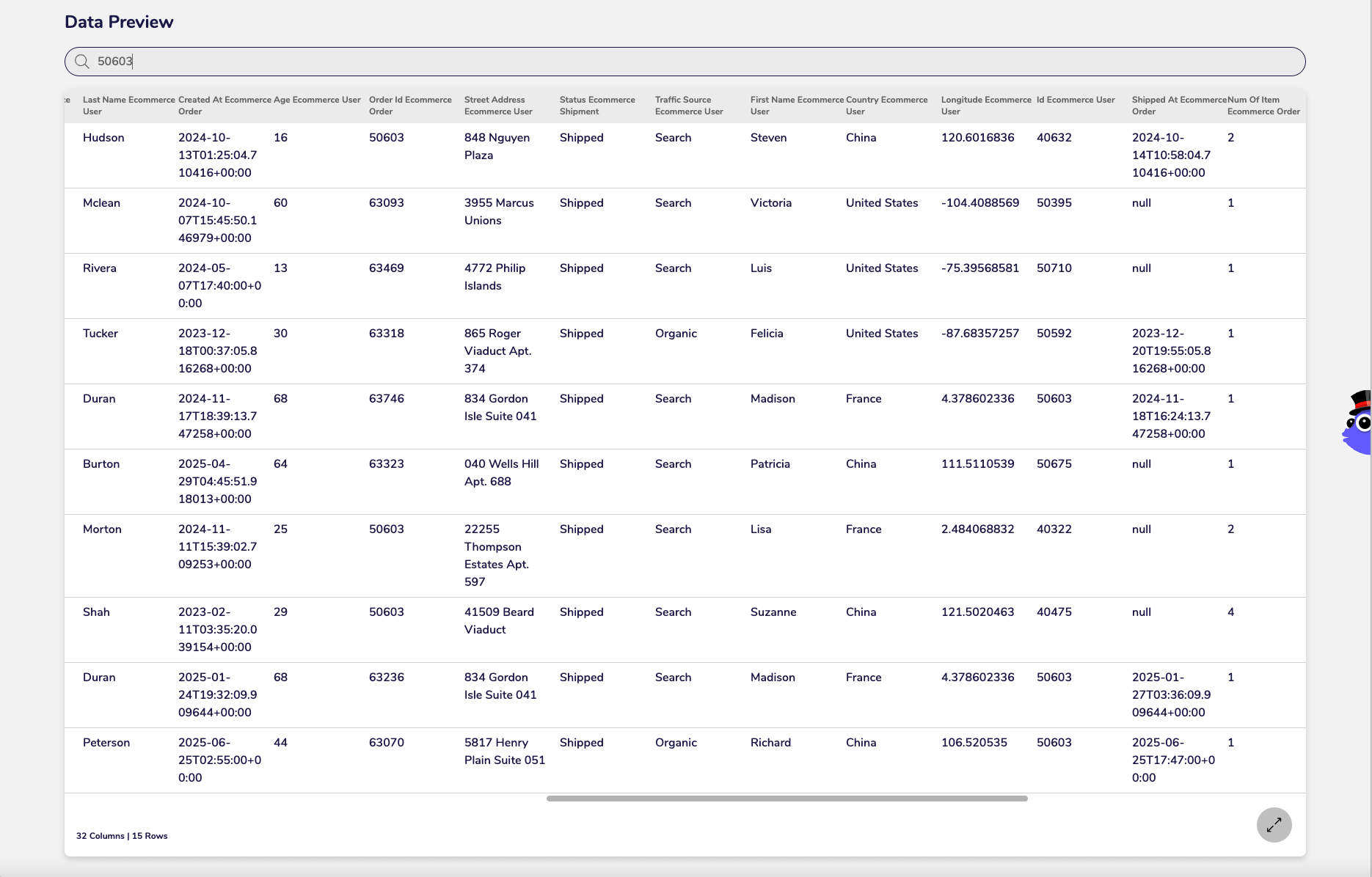
A Consume Tile that provides a "rich, wide narrative" of the event, encompassing all relevant attributes (from associated concepts and details) as they stood at the event's time. This provides a fully contextualised record for analysis
Why It Works
It's like having a perfect, unalterable ledger of every significant business action.
Instead of storing all attributes directly with the event (which would lead to data duplication and difficulty in managing change), the Event Tile stores only the relationship of keys at a point in time. This simplicity allows for insert-only operations, which inherently preserves history and makes auditing straightforward.
When a view of the event is needed, the details are rehydrated from their respective Concepts, always ensuring the attributes are accurate for the moment the event occurred.
This approach allows for a single, hardened pattern for loading events regardless of their original source, making data engineering workflows far more efficient, easier to troubleshoot, and simpler to understand.
It provides a consistent, reliable mechanism for handling complex data changes and ensuring that historical analysis always reflects the true state of affairs at the time of an event
Real-World Example
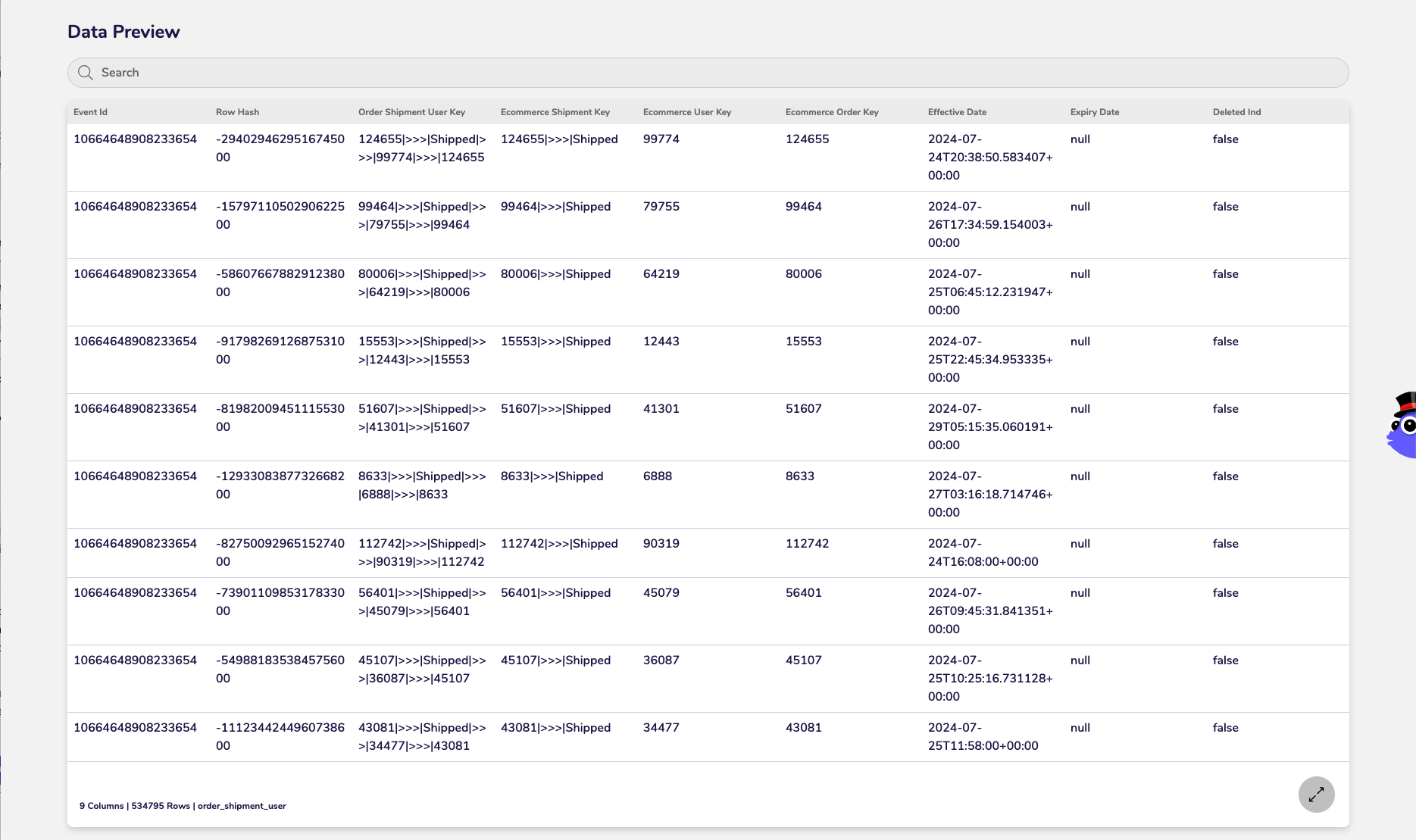
Consider a retail scenario where a "Customer Orders Product" event occurs. The Event Tile for this would simply contain keys like CustomerID, OrderID, ProductID, and the OrderDate (as the effective date). The OrderID might be chosen as the driving concept.
Later, the customer updates their address, or the order quantity changes. Because the OrderID is the driving concept, if the order quantity changes, a new event record is inserted into the Event Tile, capturing the new state. No existing records are updated.
When a user queries for the "Customer Orders Product" event data, the system automatically hydrates the Consume Tile.
This involves joining the event record with the Customer Concept's details (e.g., customer name, address at the time of the order) and the Product Concept's details (e.g., product name, price at the time of the order), and the Order Concept's details (e.g. order quantity, value at the time of the order). This way, even if the customer's address changed last week, a query about an order placed two months ago will show the address the customer had two months ago.
This pattern is also crucial for modelling complex state changes, such as an invoice moving through entered, updated, approved, and paid statuses. Each status change would trigger a new event record, providing a complete, granular history of the invoice's lifecycle.
Anti-Patterns or Gotchas
Storing detail or numeric attributes directly on the event tile: This is a major pitfall. The Event Tile should only contain keys and an effective date. Storing details or numeric values on the event tile negates its core benefits, leading to data duplication and complexity when attributes change.
Applying it to overly simple cases: For straightforward data, where attributes are self-contained and don't require complex historical context, a simple Concept and Detail (C&D) model might suffice and be more efficient. Don't force Event Tiles where they aren't needed.
Ignoring the overhead of joins during consumption: While the Event Tile itself is lean, the hydration into Consume Tiles involves joins. If not managed well (e.g., with efficient partitioning and clustering in BigQuery), this can incur significant computational cost.
Failing to define a clear "driving concept": Without a consistent rule for when a new event record should be inserted (i.e., what constitutes a "change" to the event), the data can become inconsistent or incomplete.
Directly treating native source events as-is when internal unique reporting is needed: If unique concepts embedded within a native event (like unique page titles in Google Analytics data) need to be reported on, it's often more efficient to unbundle and model them as distinct concepts rather than querying across all hydrated event
Tips for Adoption
Establish a clear three-layered architecture: This pattern thrives within a "history, designed, consume" data architecture, with Event Tiles residing in the designed layer.
Strictly define object types: Adhere to the principle that your designed layer only contains three types of objects: Concepts, Details, and Events.
Enforce insert-only behaviour: Ensure that Event Tiles are append-only. New records are inserted, never updated or deleted, to maintain a full history.
Utilise effective dating and windowing functions: Implement effective dates on Event Tiles and use windowing functions for querying to correctly pull associated details that were current at the time of the event.
Carefully select the driving concept: Clearly identify which concept's changes will trigger a new event record insertion to ensure the granularity of your event history is appropriate.
Optimise for joins: When hydrating, ensure your underlying data platform is configured for efficient joining (e.g., correct partitioning and clustering in BigQuery) to mitigate computational costs.
Standardise native event ingestion: Develop a consistent process for unbundling and re-modelling native source events (like Google Analytics) to fit the Event Tile pattern, or identify when it's more beneficial to model parts of them as standalone concepts
Related Patterns
Concepts: The fundamental "things" or entities in your data model that Event Tiles link together (e.g., Customer, Order, Product).
Details: The attributes associated with Concepts that are joined to Event Tiles during hydration to form a Consume Tile (e.g., Customer Name, Product Price).
Consume Tile: The wide, denormalised table that results from hydrating an Event Tile with its associated Concepts and Details at a specific point in time.
Activity Event: A discussed variation of the Event Tile pattern that provides another way of doing event modelling, intended for a future deep dive.
Data Vault Modelling (Link Tables): While Event Tiles share similarities with Data Vault's Link tables (representing relationships between business keys), they deviate by not directly connecting to "details" in the same way, creating a variation of the pattern.
Dimensional Modelling (Fact Tables): Event Tiles behave somewhat like fact tables as they capture business events, but they do not store numeric attributes directly. Instead, these attributes are stored in related Concepts and hydrated at the Consume layer
Press Release Template
Capability Name
Event Tile Data Modeling
Headline
New Event Tile Pattern Delivers Accurate, Time-Staged Event Narratives for Data Consumers
Introduction
Today, the AgileData team is excited to announce the adoption and refined application of our Event Tile data modeling pattern. As a core component of our three-layered data architecture, Event Tiles provide a revolutionary way to capture business processes and transactions. By modelling "who does what" at a specific point in time, this capability ensures that data consumers receive a rich, wide, and historically accurate view of events, making complex data easy to understand and use
Problem
"As a data consumer, I always struggled with understanding complex changes in our data over time. It was a real problem to query historical events accurately, especially when attributes like a customer's address changed. I also faced massive problems trying to decide what the grain of an event was, or what triggered a new event or a change to an existing one."
Solution
The Event Tile pattern addresses these challenges by specifically modeling business processes and transactions as simple collections of business keys—typically between three to five, and never more than eight. These event tables are insert-only, meaning new records are added only when a unique situation occurs. A "driving concept," such as an order, dictates when a new event record is inserted, capturing every change of state and ensuring a complete historical record.
When an event is captured, it is automatically hydrated into a "consume tile". This process involves joining the event's keys with all relevant detail attributes that were current at the exact moment the event occurred. This results in a comprehensive, time-staged narrative that provides an accurate snapshot of the business process at any given point in time, solving the complexity of querying historical changes. This approach also provides a consistent and efficient pattern for loading events, regardless of their source
Data Platform Product Manager
"With our refined Event Tile pattern, we've transformed how we manage historical data, directly solving the long-standing issue of accurately tracking complex event changes. This capability significantly enhances the auditability and integrity of our data assets, leading to a far more efficient and robust data engineering pipeline for our team."
Data Platform User
"I absolutely love that when I query an event, I now get a complete and accurate picture of precisely what happened at that exact moment in time, including all the relevant details. It makes understanding complex business processes so much clearer, and I no longer have to worry about data inconsistencies or attributes changing unexpectedly."
Get Started
The Event Tile data modeling pattern is a fundamental part of AgileData's architectural design and is automatically applied to new data product development, ensuring robust and accurate data delivery. For more details on how this capability underpins your data solutions, please speak with your AgileData Platform Product Manager.
AgileData App / Platform Example
Event Tile
Data Preview
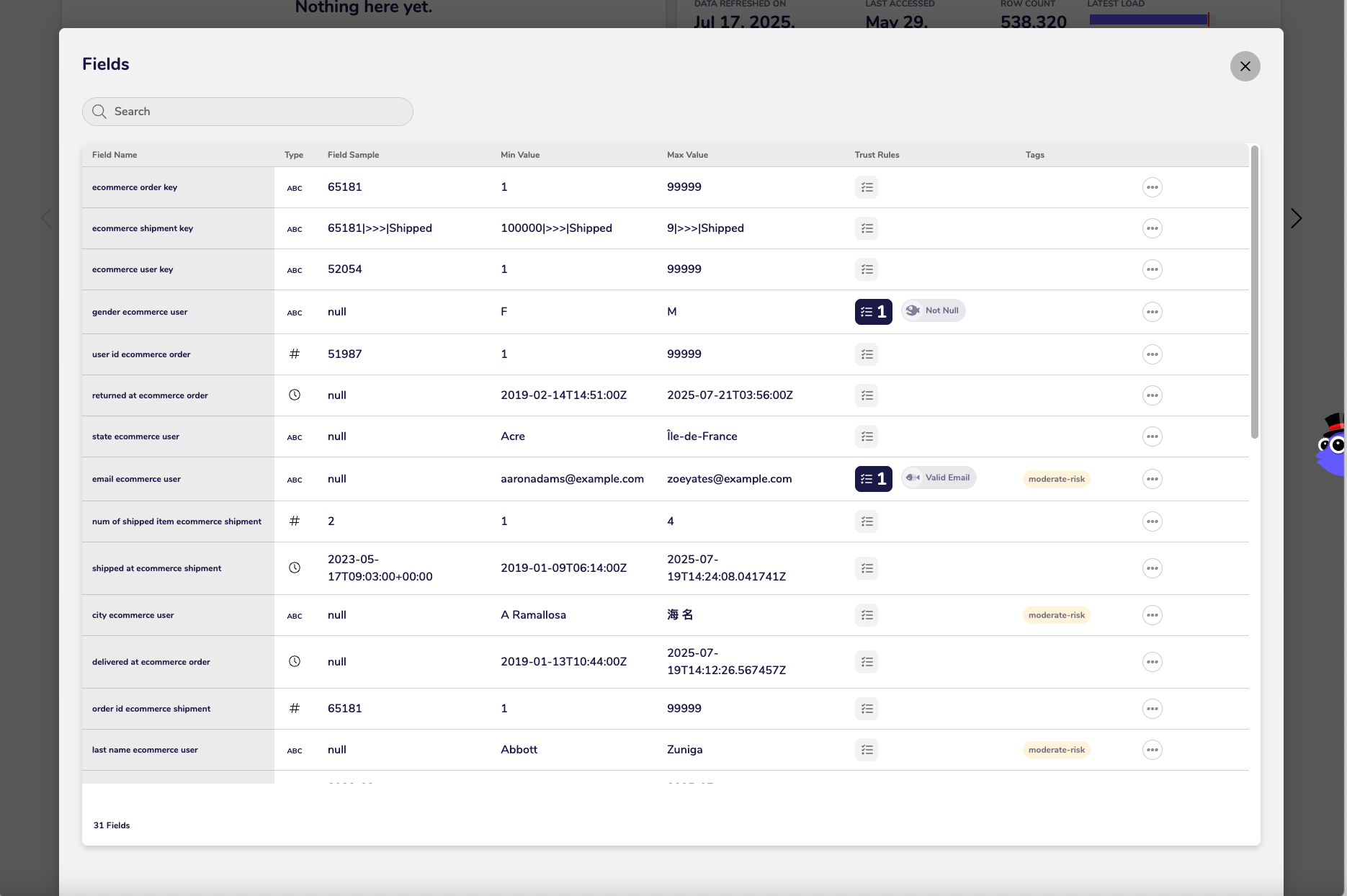
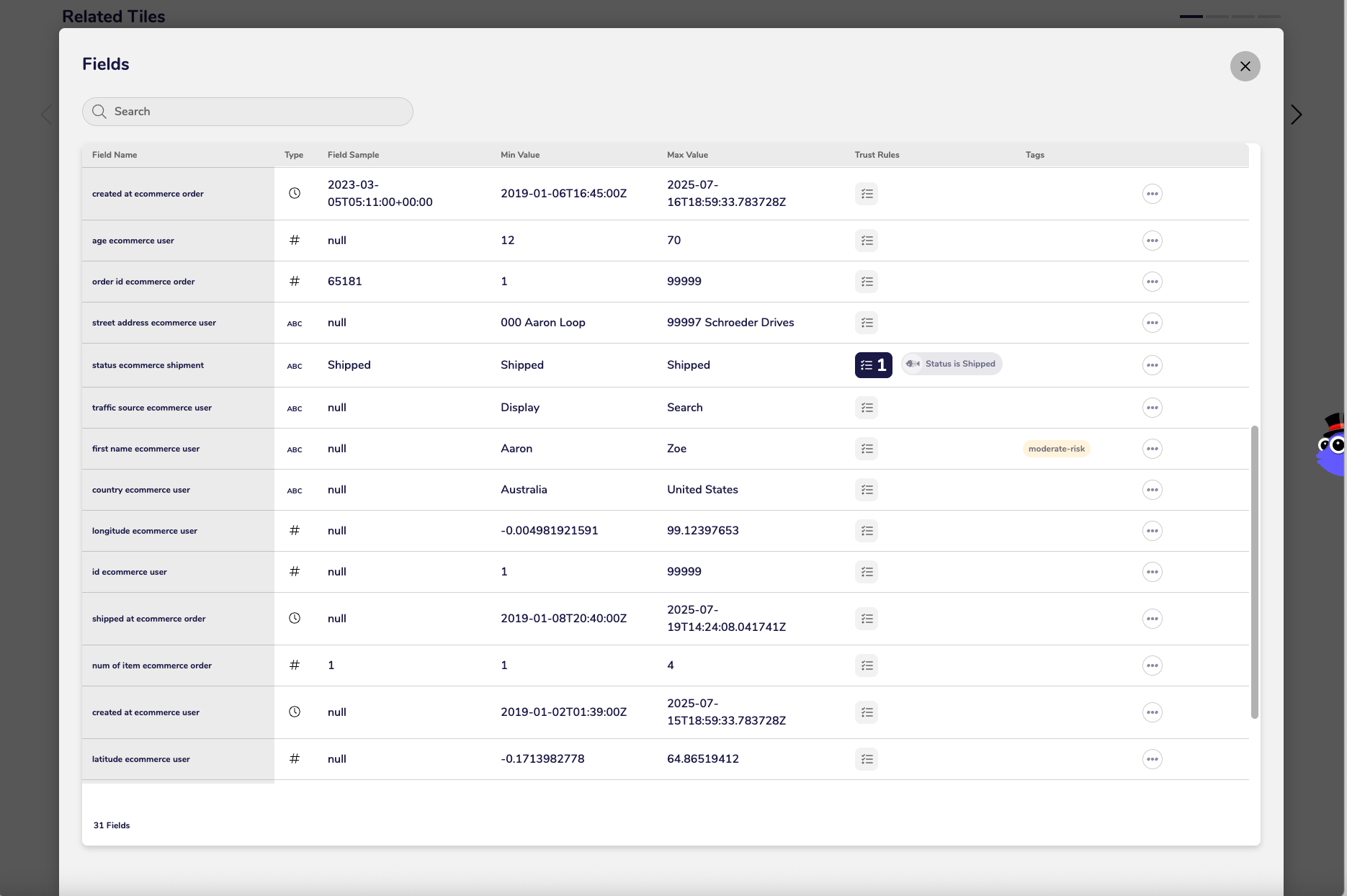
Fields (Schema)
Related Tiles


Consume Tile
Data Preview
Fields (Schema)

AgileData Podcast Episode
AgileData Podcast Episode MindMap
AgileData Podcast Episode Transcript
Shane: Welcome to the Agile Data Podcast. I'm Shane Gibson.
And I'm Nigel Vining.
Hey, Nigel, another episode in our data engineering Pattern series, and today we're going to talk about event modeling. I think what we'll do is I'll start off talking a little bit about the concept of event modeling, and then from there we can deep dive into the engineering practices and patterns that you use to make.
So we've talked before about we hold a three layered architecture. Data comes into history. We then move it into a designed layer where we measure it all up, make it fit for purpose, and then we have a consumer layer where everybody comes in and uses that data. Within that designed layer, we have three major object types.
We have, a concept, which really is a thing we see. It holds effectively a key for a thing that we know exists. Customers, employees, suppliers, orders, payments. We another tile type object type, which is detail, which holds the attributes about those things. So customer name, customer date of birth, supplier type, employee address. And so those details are bound next to the concepts. And then the third type we have is an event which basically says we saw a business process or a transaction happen. And within those event tiles, we have two types that we deploy. The first one is our standard event. This is where we see a business process happen a customer orders a product, a customer pays for an order, somebody ships the product or the order to the customer.
The customer returns a product to an order. And a little while ago, we introduced a second patent that we used conceptually called an activity event. And we can talk about that next time. But for now, let's deep dive into this idea that we've actually got a business process or a business event and we model it as an event.
Nigel: Yeah. So effectively what we do to make this magic happen is an event tile is basically just a collection of keys that something happened at a point in time, and these are all the business keys that are associated with it. So as you said at this date. This customer id, this order id, this product id, we effectively create that row in our event table of customer orders product, and then the next step is we automatically hydrate that event into a consumed tile.
So we effectively take that event and we join it to the details that are associated with it at that point in time. So the consumer's quite wide because effectively it's got all the customer attributes at that point in time. All the order attributes in a nice wide table, and that's all done at each point in time.
So then when something else happens with that order, or it's changed or it's status changed, we effectively insert another event record, which generates another consumer record out the other side to reflect the change to some aspect of that. And it also picks up all the same product attributes and customer attributes at that point in time.
So it's quite a simplistic thing because the tile is really quite boring. It's just a whole lot of business keys. But then when we hydrate it into a consume, it becomes a really rich, wide narrative for these events that are happening.
Shane: And so effectively that tile just holds a small number of columns.
And unique IDs or keys sitting in there. So we've found that when we model it, it's typically no more than seven or eight keys in that table.
Nigel: Yep. Seven or eight is getting up there. I haven't seen many past four, but Yep. I think seven is pretty much acknowledged as generally as wide as you go for those keys.
I haven't seen any business processes that tend to need more than that,
Shane: and because we use that format from Lawrence Co Beam of who does what. We end up with event tables that are always more than two keys. So we don't relationally model our event tables as two-way links. We're effectively modeling that core business process using that language.
So we always have, like you said, three to four to five concepts. Part of an event.
Nigel: Yeah. And it is generally , some variant of a, who does what? Who being a customer, for example, or a user that does being what they've done. They've ordered something. They've created something. And then the third part of the care is usually the what?
The thing. They've acted upon a product.
Shane:And one of the key things for me is because the orbit. The thing that typically holds a value, like quantity dollar is still a concept and it's part of that event the like a fact. Table from dimensional modeling, except we don't store the numeric attributes in that event.
We get those attributes when we build the consume because those attributes are held by the order concept . And if the event is customer orders product, then we know that the order quantity order value is sitting there and we rehydrate it. But it's different to a fact from dimensional modeling because we don't hold any attributes at all on that event tile, do we?
There's no detail on the event tile if I ever go and query it. It's just a bunch of keys.
Nigel: Yes. The detail comes from effectively the. Concept keys, concepts are associated with attributes. So yes, we don't store any attributes on that event table because we don't need to because they're sitting in our detail tables.
When we hydrate that we get the applicable. Detail attributes at the point in time.
Shane: The other thing is it's a form of a link table from DataBot modeling, but we don't follow the DataBot 2.0 standard where there is detail directly connected to that link table event table. In our term, it's not a link table because we don't follow the rules.
So we take the part of the patent we liked, and we created , a variation or our own patent for it. The other thing is those event tables are insert only. So we only ever insert new records in there. We never do any updates.
Nigel: That is correct. We check if the unique situation, that we're about to put in there is has already happened.
And if it hasn't, we then insert that, , a new row of keys effectively.
Shane: And then how do we deal with effective dating or dating those events?
Nigel: So what we do is the event table has an effective tape. So we say at this point in time, or this business effective tape, this customer had a relationship with this order and this product.
So we've effectively, we've created our slice, and then when we join the attributes to that road to hydrate it, we basically pick the attribute that was current at the point in time of that event. So we say what customer record? Was the one that was applicable because it may have changed since the customer may have gone on and done something else.
So they've updated their address, they've updated something else, or their status or whatever. So what we do is when we hydrate that row and the consume, we hydrate it at the point in time the event was created. So it is always accurate for when it occurred.
Shane: And then there's also this concept of a driving concept we call it.
Do you wanna talk me through that and how that works from an engineering point of view?
Nigel: So we picked the first concept in the event as our driving concept, and that's the one we look to. Changes occur. We insert a new event row, so customer orders product, the driving concept in that case is likely to be the order, because the order is created, the order is updated, it's fulfilled, dispatched, so we want all those changes of state of the order.
So that's the one that we drive a new record. So when their order is updated. We insert new record and we pick up the applicable customer and product at the time. If that order's not updated, we don't create a new event row because we are not driving off the customer or the product. So if the customer's updated, it doesn't matter because this is an order event.
Shane: just to clarify that when we talk about order being updated, what we're talking about is a new order Id turning up, so if a new order number turns up. Of an.
Quantity changed. We will then go and drive an insert of an event that related to that order changed.
Nigel: For that instance, we would, because the order is the driver, so that order has changed. So we want a new record to basically capture that the order has changed. So when we hydrate that record, you can see that the order quantity has changed on it.
Okay. So we're
Shane: effectively doing an insert of every. Of that event, driving off the driving concept. Yep. And then we don't end date any records, so now we are using a windowing function to see which event was active at a certain point of time. Yes. And therefore, what details relate to it? That is exactly right.
So what happens when we go and get data from somewhere like Google Analytics, which is another type of event, and it's not really customer orders product, it might be individual views webpage. Do we treat that differently
Nigel: at all? We've done both versions of this. We went through a phase of treating Native Source events as events, and then we went through a phase of basically saying an event in that situation can be treated as a concept because every row from GA four is effectively a concept because it's a marker that someone.
Something and it was captured. And then the second part of it is the detail is what that something is. So GA four is a little bit unique in that it arrives as an event. So we can treat it as a concept or we can model it as event by splitting keys out. They both get the end result. One's just a little bit more technical 'cause you're unbundling the event just to turn
Shane: it back into an event.
If we think about that, so we take what is an event? Record, and then we unbundle it to its component parts, a bunch of concepts and details and the idea that there was a relationship or an event happened, and then we rehydrate it back to itself because then we have a single Pattern for how we load events regardless of what type of data comes in.
And that makes us far more efficient in terms of hardening our code and troubleshooting and understanding the stuff.
Nigel: There is use cases where we would split an event that's coming in when we want to report on the individual concepts that are bundled in it. So if there's a requirement to report on all the unique, say for example, page titles coming through, that's where splitting it out into a page title or page.
Concept makes a lot of sense because then you effectively have this master tile, which has all your titles in it. So for reporting, you can go straight to that. You don't have to go through a convoluted Pattern just to get a unique title. As
Shane: one of the examples there is we have customers that hold customer attributes on their Google Tag Manager GA four Data.
So when it comes through, and we know we're gonna have to report on how many of those unique things there are. It's much cheaper for us to break those out to be concepts so we can report on them because they are things we wanna count and manage versus having to query across all the hydrated events to then find that attribute.
And on that, if you think about it, we're creating some event tiles. And then we're having to join to the concepts and then join to the details. There's lots of joins and we run on BigQuery. So isn't that an anti-patent to join all that data? Doesn't that cost us a fortune?
Nigel: That is a really good point.
Joins do come with an overhead and a cost and a computational cost. We mitigate some of that by making sure the amount of partitions we are presenting to join and. We are to effectively bring down that overhead, but join we a bit overhead.
Doing the things that keep it efficient.
Shane: What's the anti-patent for event tiles, do you reckon? When wouldn't we use this Pattern? We did try using Season Ds only because effectively I could create a concept of an order and then I could put the customer and the product and the detail for it. Yes, but we found as soon as we got complex changes within the event, like the customer's address changed.
Then it became a real problem to try and query it and event solved it because it gave us a view of everything about that event at the time the event happened. I can't think of an anti Pattern when we wouldn't do it. I think if we weren't modeling exactly the way we are modeling, we probably wouldn't use event times if we didn't have the simplicity of concepts, details, and events as being the only three types of objects that we model in our design layer.
We may have done something different.
Nigel: Yeah, season Ds definitely have their place and because it's really easy to take ized data, to wrap it in a concept and the detail and then rehydrate it as a consume. And for some data sets, that's absolutely fine 'cause we pass it straight through. And that's all it is because the concept is really simple.
It might be simple attributes about, , a user. So we've got a user ID as the concept, and then the user detail is the user's name and login and stuff. So it's a really simple thing and it's self-contained. We get a file of updates for users when they last logged in, and that's a good example of a c and d, and we just basically rehydrate that as a user tile.
We've got a unique list of users in the concept. And that's fine. And we might just run that as it is. And then as you said, we may have another consume, which is something else, and then we would create a rule to put them together at the consume layer, because sometimes that is just straightforward.
Shane: And I think that's the simple case.
And then we get the complex case, which is things like status change, invoice was entered, invoice was updated, invoice was approved, invoice was paid. And so that. Used to always cause me massive problems trying to decide what the grain of the event was, what was the trigger to say that a new event turned up or a change to that event happened, which probably leads into this idea of activity events that added as a another way of doing the event modeling for a whole bunch of reasons.
But I think we'll keep that one for another day. So I hope everybody has a simply magical day.
This was a really complex one to try and explain in a simple way, and i'm not sure we have nailed it.
Whats your thoughts?
------
I have also added a new section to the Agile Data Engineering Pattern posts.
A Mind Map of the Podcast episode generated by Google NotebookLM (how did I miss that feature turning up!)
This is cool. I my Kimball-centric view, it is a change-tracked / type2scd'ed fact table with a couple of dims around it. Probably more efficient from a storage point of view, though.
The terminology is a bit foreign, but I'm coming around to it.
I wonder how to tackle this when sourcing from a system of capture that does not track granular changes. Perhaps something like the CDC on its database, but then we may not know who did that change necessarily.